|
Читайте также: |
Термин «статистика» происходит от лат. «status», то есть «состояние» и первоначально связывался с системой описания фактов, характеризующих состояние государства.
Статистика – раздел математики, посвященный математическим методам, систематизации, обработки и использованию данных.
Классификация разделов статистики:
1. Сбор статистических сведений
2. Статистическое исследование – данные анализируются для выяснения закономерностей, которые могут быть установлены лишь на основе массовых наблюдений
3. Разработка приемов статических наблюдений и анализа статистических данных (математическая статистика)
Основные методы математической статистики относятся к двум разделам:
1. Теория статистического оценивания параметров распределения
2. Теория проверки статистических гипотез
Основные понятия статистики:
Статистические данные – сведения об объектах из достаточно большой совокупности, обладающих определенным набором признаков.
Типы признаков:
1. Количественные признаки – могут быть измерены для каждого объекта числом (возраст, вес, давление и др.). Большинство статистических методов разработано именно для таких признаков.
2. Качественные признаки – не могут быть измерены количественно, как правило, они указывают в текстовой форме категорию, к которой относится объект. Качественные признаки так же допускают измерение: можно подсчитать количество объектов, попадающих в каждую категорию признака (найти частоту встречаемости этой категории). Только на уровне совокупности происходит превращение качества в количество.
Статистическая совокупность – множество объектов, характеризуемых некоторым количественным или качественным признаком.
Генеральная статистическая совокупность – это статистическая совокупность, состоящая из всех объектов, характеризующихся выбранным признаком.
Выборочная статистическая совокупность (выборка) – статистическая совокупность, состоящая из некоторого количества объектов случайным образом, выбранная из генеральной статистической совокупности. Случайность необходима для репрезентативности (представительности) выборки, то есть свойства выборочной совокупности должны соответствовать генеральной совокупности.
Выборка – множество значений Х1, Х2, Х3, Хn из всех значений Х. Свойства выборки являются приближенными оценками свойств генеральной статистической совокупности.
Оценка свойств генеральной совокупности по выборке
Структура выборочного метода:
1. Создание выборки
2. Выявление свойств выборочной статистической совокупности и получение оценок ГС
3. Определение величины ошибки, в полученных оценках ГС
Дискретные интервальные вариационные ряды – используются для систематизации сведений о выборки и для построения эмпирической функции распределения.
Количественно изменяющийся признак Х носит название варьирующего признака, а его конкретные значения называются вариантами.
Х1, Х2 … Хk – варианты
Числа, показывающие, как часто встречается тот или иной вариант в составе данного ряда, называются частотами.
m1, m2 … mk
Ряд, в котором сопоставлены варианты и соответствующие им частоты, называются вариационным рядом.
m1 + m2 + … mk =∑ mi= n
Относительная частота элемента:
Pi = mi / n
Формы представления вариационного ряда:
1. Табличная форма
2. Графическая форма
Результаты наблюдений, представленные в такой таблице, называют статистическим дискретным рядом распределения. Его изображением является полигон частот; для его построения откладываются точки с координатами Х и m и соединяются отрезками.
В случае если количество вариантов очень большое или Х является непрерывной случайной величиной с неизвестной плотностью вероятности, то результаты можно представить в виде статистического интервального ряда распределения.
Построения интервального ряда распределения:
1. Всю область значений признака Х разбивают на небольшое количество интервалов
2. Определяют количество значений Х, попадающих в каждый интервал (частоту интервала)
3. Рассчитываем относительные частоты
Статистическим интервальным рядом распределения называется таблица, в которой первая строка содержит границы интервалов, вторая строка значения частот m или p. Графическим изображением такого ряда является гистограмма относительных частот. Гистограмма состоит из прямоугольников, основаниями которых служит значение дельта Х (ширина интервала), а высотами плотности частот. Огибающая этого графика имеет смысл эмпирической плотности вероятности распределения.
Точечные и интервальные оценки параметров распределения по данным выборки.
Точечная оценка – оценка, даваемая одним числом (точкой на числовой оси), которому приближенно равна оцениваемая характеристика.
Генеральное среднее (Х)
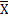 = 1/N ∑ хi
= 1/N ∑ хi
Оценкой генерального среднего является выборочное среднее.
 = 1/n ∑ mi xi
= 1/n ∑ mi xi
Генеральная дисперсия:
α = 1/N ∑ (xi – X)2
Выборочная дисперсия:
S2 = 1/n ∑ mi (xi – x)2
Оценкой генеральной дисперсии является выборочная дисперсия. Наилучшей оценкой генеральной дисперсии является исправленная выборочная дисперсия.
Исправленная выборочная дисперсия:
S2= 1/n-1 ∑ mi (xi – x)2
Если объем выборки меньше или равен тридцати, то пользуются исправленной выборочной дисперсией; если же объем больше тридцати, то можно пользоваться просто формулой для выборочной дисперсии. Наилучшей оценкой для генерального среднего квадратического отклонения является выборочное среднее квадратическое отклонение, равное корню квадратному из выборочной дисперсии.
Интервальные оценки.
Чтобы дать представление о точности и надежности полученной оценки (точечной) используют доверительные интервалы и доверительные вероятности, то есть ответ задается в виде интервала на числовой оси.
Доверительным называется интервал, который с заранее заданной надежностью гамма покрывает оцениваемый параметр. Это может использоваться для оценки мат. ожидания случайной величины Х, распределенной по нормальному закону при известном среднем квадратическом отклонении.
Надежность (доверительная вероятность) обозначается буквой гамма – это степень уверенности в том, что доверительный интервал будет содержать истинное значение параметра Х (среднее) генеральной совокупности. Традиционно значение гамма берут равным 95% и по этому значению находят ширину доверительного интервала.
Распределение Стьюдента:
Пусть величина Ч имеет нормальное распределение. Уильям Госсек исследовал свойства величины Т.
Т = (Х –х)/ Sx
Величина Т отражает связь между отклонением Х от х и среднеквадратическим отклонением с учетом объема выборки. Сейчас говорят, что величина Т подчиняется распределению Стьюдента, свойства которого нам известны. Тогда обозначив, дельта х полуширину доверительного интервала, мы можем записать формулу Стьюдента.
При этом учитывается число степеней свободы f = n – 1
(табл. 2)
Из генеральной совокупности извлечена выборка объема 50, после анализа выборки был построен ряд распределения. Оценить с надежностью 95% математическое ожидание величины х, если мы считаем, что х распределена нормально. Находим точечную оценку х (среднее) и находим среднее квадратическое отклонение.
Для нормального распределения известно, какая часть совокупности попадает в любой интервал вокруг среднего значения:
67% всех выборочных средних попадут в интервал ±S
95% в интервал ±2S
97% в интервал ±3S
Последовательность действий при построении доверительного интервала:
1. По выборке вычисляются х и s
2. Выбирается доверительная вероятность у подсчитывается f и соответствующее им значение параметра t
3. Вычисляется дельта х
4. Строится интервал х± дельта х
Определение объема репрезентативной выборки
T = (Δх корень из n)/S
n – необходимый объем выборки для того, чтобы выборка была репрезентативной.
В этой формуле S получается из анализа предварительной выборки (пробной) и неизвестна заранее, поэтому такое исследование является двухэтапным.
Вычисление случайных погрешностей измерений
Случайными называются погрешности, которые при многократных измерениях в одинаковых условиях изменяются непредсказуемым образом. Случайны погрешности формируются множеством независимых факторов и не могут быть ликвидированы полностью, однако их можно учесть при измерении.
Измерения бывают:
1. Прямые измерения – результат получается с помощью измерительного прибора
2. Косвенные измерения – результат получают с помощью расчетов (измерение объемов площадей)
Оценка случайных погрешностей прямых измерений (серия измерений)
Серия измерений проводится в одних и тех же условиях. Число измерений в серии обозначим n. Тогда наилучшей точечной оценкой истинного значения измеряемой величины Х является среднее арифметическое всех измерений.
Наилучшая интервальная оценка истинного значения дается в таком виде:
Хистинное =
Определение полуширины интервала дельта Х:
ΔХ = tгамма (f) * Sх (среднее) – формула Стьюдента
ΔХ называется абсолютная погрешность измерений.
Порядок вычисления интервальной оценки для истинного значения Х:
1. Дать точечную оценку истинного значения Х (среднее)
2. Определить полуширину интервала дельта Х
3. Дать интервальную оценку
Хистинное = ± ΔХ
Пример: с доверительной вероятностью гамма = 0,95 дать интервальную оценку истинной массы вещества, содержащегося в одной капсуле, если в результате измерений этой массы были получены следующие значения: 10, 11, 12, 11 мг.
Х = (10+11+12+11) /4=11
Sx=0,408
f = n -1 = 4-1 = 3
t0,95 (3) = 3,182
ΔХ = t0,95 (3) * 0,408 = 3,182 * 0,408 = 1,298
Х = 11 ± 1,298
Оценка случайных погрешностей косвенных измерений:
Наилучшая точечная оценка истинного значения Y – это среднее значение Y, вычисленное от средних значений Х.
Значения среднего квадратического отклонения для Y (среднее):
Sy (среднее) = (сумма частных производных * Sx (среднее))2
Вычисления абсолютной погрешности для переменной Y ведется по формуле Стьюдента:
Δy = tгамма (f) Sy (среднее)
Пример: проведем обработку результатов эксперимента по измерению ускорения свободного падения g. В ход эксперимента выполнено прямое измерение времени падения t стального шарика с высоты h. Оба измерения являются многократными (n=20) прямыми измерениями. После их обработки были получены следующие данные:
Даем точечную оценку для среднего значения g.
Вычисление относительной погрешности y:
E = (Δy * 100%)/y
Е = 1,86/9,8 * 100% = 20%
По величине относительной погрешности можно судить о качестве измерений.
Проверка статистических гипотез о законах распределения
Статистическая гипотеза – предположение о виде или параметрах закона распределения вероятности. Различают параметрические и не параметрические гипотезы:
1. Параметрические гипотезы относятся к оценке параметров распределения (мат. ожидание, дисперсия и т.д.)
2. Не параметрические гипотезы относятся к виду закона распределения
Понятие нулевой и альтернативной гипотезы:
Нулевая гипотеза (Н0) – основное проверяемое предположение об отсутствии различий, отсутствии влияния фактора, эффекта, равенство нулю, значение выборочных характеристик.
Конкурирующая или альтернативная гипотеза (Н) – выдвигает предположения о наличии различий или действующего эффекта.
Статистическую гипотезу никогда нельзя доказать по результатам выборки, всегда возможны ошибочные решения двух видов:
1. Ошибка первого рода – гипотеза Н0 отвергается в том случае, когда она верна. Допустимой вероятностью такой ошибки традиционно считают 5%.
2. Ошибки второго рода состоят в принятии гипотезы Н0 в том случае, когда она в действительности неверна.
Альтернативные гипотезы принимаются или отвергаются тогда и только тогда, когда опровергнута нулевая гипотеза.
Уровень значимости – вероятность ошибки первого рода при принятии решения.
Общие принципы проверки статистических гипотез: процедура проверки нулевой гипотезы включает следующие этапы:
1. Задается допустимая вероятность ошибки первого рода (уровень значимости)
2. Выбирается статистика критерия
3. Ищется область допустимых значений
4. По исходным данным вычисляется экспериментальное значение статистики критерия
5. Если экспериментальная статистика критерия принадлежит к области принятия нулевой гипотезы, то нулевая гипотеза принимается. В обратном случае проявляется альтернативная гипотеза.
Выдвижение нулевой гипотезы при проверке законов распределения:
Сначала проводится предварительная оценка параметров эмпирического распределения:
1. Построить вариационный ряд частот
2. Построить гистограмму плотности относительных частот
3. Построить статистическую функцию распределения относительных частот
4. Оценить эмпирические параметры распределения (мат. ожидание, дисперсия, сигма)
5. На основании полученных оценок выдвинуть и проверить гипотезу о характере распределения с помощью критериев согласия
Критерием согласия называют величину, с помощью которой оценивается различие между другими величинами и свойства которой известны.
Рассмотрим критерии Пирсона (хи-квадрат), которые часто используются для проверки закона распределения случайной величины.
Распределением хи-квадрат с k степенями свободы называется распределением суммы квадратов k независимых случайных величин, распределенных по стандартному нормальному закону.
Какова процедура использования критерия хи-квадрат?
1. Определяем хи-квадрат критическое по стат. Таблицам
2. Сравниваем хи-квадрат наблюдаемое и хи-квадрат критическое по следующим правилам:
· Если хи-квадрат наблюдаемое меньше, чем хи-квадрат критическое, тогда нулевая гипотеза принимается, различия считаются незначительными, а эффект отсутствующим.
· Если хи-квадрат наблюдаемое больше, чем хи-квадрат критическое, тогда принимается альтернативная гипотеза, различия в данных считаются значительными и не согласующимися с предполагаемым видом распределения.
Для перевода числа из десятичной системы счисления нужно разделить его на основание и продолжать делить его, пока частное не станет равно нулю. Значение получившихся остатков, взятые в обратной последовательности, образуют искомое число.
Архитектура ЭВМ: большинство современных компьютеров построены с использованием принципов Фон Неймана.
Принципы:
1. Компьютер состоит из нескольких основных устройств, связанных между собой.
2. Принцип двоичного кодирования – символы нуль и один, которые соответствуют двум состояниям ячейки памяти (заряжено, разряжено)
3. Принцип однородности памяти (принцип хранимой программы) – и программы и данные могут храниться в одной и той же памяти, над командами можно осуществлять одни и те же действия, что и над данными
4. Принцип адресуемости памяти – условно можно считать, что память состоит из пронумерованных ячеек и в любой момент времени доступна любая ячейка памяти. Блоком ячеек так же можно присваивать имена.
5. Принцип последовательного программного управления – программа состоит из команд, которые последовательно выполняются друг за другом
6. Принцип условного перехода – с помощью команды условного перехода можно менять последовательность выполнения команд в зависимости от значения данных
Архитектура ЭВМ, основанная на принципах фон Неймана.
Совокупность технических устройств компьютера называют аппаратным обеспечением.
Блоки компьютера находятся в системной блоке (железный ящик), память, процессор, периферийные устройства. Процессор – главная микросхема компьютера. Основой современных компьютеров является магистрально-модульный принцип организации. Модульный принцип позволяет пользователю комплектовать нужную конфигурацию компьютера, модульная организация опирается на магистральный принцип обмена информации между устройствами. Магистраль (системная шина) – система связей, соединяющих все устройства компьютера, представляет собой много проводную линию, выполненную на материнской плате компьютера. Магистраль включает в себя три многоразрядные шины:
1. Шина данных – передает данные в любом направлении между различными устройствами
2. Шина адреса – передает адреса, используемых устройств, и активирует работу всех внешних устройств по команде процессора. Сигналы передаются только от процессора к устройствам.
3. Шина управления – передает сигналы, определяющие характер обмена информацией, то есть сигналы управления (команды насчитывания или запись информации)
Системная плата – основной аппаратный компонент компьютера. На ней смонтированы:
1. Магистраль обмена информацией
2. Разъемы для установки процессора памяти и других микросхем
3. Разъемы для установки контроллеров внешних устройств
Быстродействие всех этих устройств может сильно различаться, поэтому на системной плате устанавливаются специальные микросхемы, включающие в себя контроллер оперативной памяти (северный мост) и контроллер периферийных устройств (южный мост), которые согласуют работу этих устройств. Северный мост обеспечивает обмен информацией между процессором и оперативной памятью по системной шине. К нему подключаются шины, обеспечивающие обмен информацией с видеокартами. Южный мост обеспечивает обмен информацией между северным мостом и портами для подключения периферийного оборудования (контроллеры жестких дисков, звуковые карты, шины USB, мышь, клавиатура и т.д.).
Обозначения шин и портов подключения:
1. Шина взаимодействия периферийных устройств
2. Ускоренный графический блок
3. Шина подключения памяти
4. Последовательные порты
5. Параллельный порт
6. Универсальная последовательная шина
7. Базовая система ввода-вывода – обеспечивает первоначальную загрузку программ компьютера и тестирует аппаратное обеспечение компьютера. Ее наличие позволяет запустить операционную систему.
Закон Мура – удвоение сложности микропроцессоров происходит приблизительно каждые два года.
Оперативное запоминающее устройство содержит программы, которые выполняются в данный момент и данные, используемые этими программами. После выключения компьютера вся эта информация пропадает, если не была сохранена в постоянном запоминающем устройстве.
Жесткий диск – ПЗУ, которая обычно содержит программы операционной системы, информацию, необходимую для загрузки компьютера и любые другие данные. Каждый логический диск, создаваемый на жестком диске имеет свое имя.
Поколение ЭВМ:
1. 1940-60 гг., вычислительный элемент – электронные лампы, быстродействие (10-20 тыс. операций в секунду), наиболее распространенный язык – ассемблер.
2. 1960-64 гг., вычислительный элемент – транзисторы, быстродействие (1, 2 миллиона оп-ций в секунду), появилась внешняя память на магнитных баранах и магнитных лентах. Были разработаны языки программирования высокого уровня.
3. 1964-72 гг., вычислительный элемент – интегральные схемы, быстродействие (до 300 миллионов операций в секунду), появились первые микро ЭВМ, предназначенные для одного пользователя. Появились первые операционные системы.
4. 1974 по настоящее время, вычислительный элемент – микропроцессоры, быстродействие (миллиарды операций в секунду), появились доступные по цене персональные ЭВМ с жестким диском.
5. Настоящее время; основаны на использовании нано технологий. Используются нейросетевые модели. Происходит отказ от Фон Неймоновской архитектуры.
Общие принципы анализа медицинских данных
Использование стат. данных в биологии и медицине
Выделяют три основных этапа развития любой науки:
1. Эмпирический – накопление и описание фактов, частичная систематизация.
2. Теоретический – анализ и синтез накопленных фактов в виде непротиворечивых теорий; сбор и накопление стат. данных.
3. Математический – на базе накопленных стат. данных исследуются количественные закономерности и создаются мат. модели явлений и объектов.
Использование средних величин:
Среднее арифметическое – является «центром тяжести» распределения. Среднее арифметическое обладает удобными стат. свойствами – сумма отклонений отдельных значений от средней арифметической равна нулю. Поэтому СА удобно использовать в случае симметричных распределений (нормальное распределение). Однако СА чувствительно к влиянию крайних значений: под воздействием одного очень большого значения среднее может увеличиться, поэтому СА не применяются для описания ассиметрично распределенных данных.
Мода – наиболее часто встречающийся вариант ряда.
Медиана – такое значение признака Х, которое приходится на середину ранжированного ряда и делит его на равные по числу единиц части справа и слева от медианы. Свойство медианы – сумма абсолютных величин отклонений вариант от медианы меньше, чем от любой другой величины. Медиану часто используют для оценок среднего в случае не симметричных распределений.
Сбор и представление данных:
Диаграмма рассеяния – диаграмма изображающая значение двух переменных в виде точек на декартовой плоскости.
Методы сбора данных
1. Поперечное обследование – обследование каждого пациента проводится только один раз, при этом выявляется типичная картина заболевания по совокупности наблюдаемых симптомов. Не применяется при исследовании болезней с длительным течением.
2. Продольное обследование – производят постоянное наблюдение за группой пациентов в течение определенного времени. Если есть критерии формирования группы и длительное наблюдение, то это проспективное исследование. Продольное обследование по архивным данным называют ретроспективным. В качестве стандартного представления данных при продольных исследованиях строятся кривые выживания.
Тип №1 – кривая дрозофилы. Характерны для видов с высокой выживаемостью молодняка, а также для человеческих популяций развитых стран с хорошим уровнем медицины и экономики.
Тип №2 – кривая пресмыкающихся. Характерен для видов с постоянным уровнем смертности в течение жизни, а также для человеческих сообществ с хорошим уровнем экономики и плохой медициной (Римская империя).
Тип №3 – кривая устрицы. Характерен для сообществ с высокой детской смертностью и для развивающихся стран (Африка).
Временные ряды – по вертикали количественная характеристика.
Виды ПО:
1. Базовое ПО – предназначено для эксплуатации и тех. Обслуживания компьютера. Программа ввода–вывода – самый низкий уровень ПО, управляет периферийными устройствами, тестирует аппаратную часть компьютера, запускает драйвера и программы-загрузчики, то есть обеспечивает первоначальную загрузку компьютера. Операционная система – комплекс программ для управления компьютером.
2. Прикладное ПО – игры, редакторы, программы воспроизведения и т.д.
3. Программы, создающие другие программы (программные среды языков программирования).
Программные средства обработки и анализа медицинских данных
EXCEL – редактор электронных таблиц.
Дисперсионный анализ – позволяет выявить природу отклонений от средних значений, наблюдаемых в массиве данных.
Корреляционный анализ оценивает взаимосвязь двух наборов данных с помощью коэффициента корреляции, если коэффициент близок к единице, говорят о положительной корреляции, если к минус единице, об отрицательной корреляции. Если коэффициент близок к нулю, корреляции нет.
Описательная статистика – команда, которая позволяет получить основные характеристики выборки (среднее, дисперсия, сигма).
Выборка – создает выборку из имеющихся данных по разным критериям.
Т-тест позволяет рассчитать значение критерия Стьюдента в различных ситуациях.
Программа статистика – пакет программ, работающий с электронными таблицами и позволяющий использовать готовые сценарии стат. исследований и обработки данных. Все методы обработки данных разбиты на модули в соответствии с разделами стат. анализа.
Модули:
1. Основные статистики и таблицы – содержит основные описательные статистики, методы анализа таблиц, инструментарий для разведочного анализа данных.
2. Кластерный анализ – позволяет оценить близость между различными группами данных.
3. Анализ временных рядов – позволяет оценить качество данных и составить прогноз.
При запуске программ из каждого модуля вы получаете доступ ко многим процедурам:
1. Анализ данных
2. Управление данными
3. Добыча данных
4. Визуализация данных
MatLab – пакет прикладных программ, создающихся с 70-х годов прошлого века, для решения задач тех. Вычислений и стат. анализа. Имеет свой язык и требует спец. Изучения.
Представления массивов данных в виду векторов и матриц:
Главным объектом при работе с MatLab является массив. Массив хар-ся размерностью и размером. Простейшими массивами являются строки, столбцы, матрицы и кубические массивы. Строка или столбец – массив, имеющий размерность равную единице. Матрица (таблица) – массив с размерностью два. Трехмерный массив – массив с размерностью три. Массивы могут быть и больших размерностей – четырех, пяти и т.д. количество элементов в строке или столбце. Каждый элемент однозначно задается в массиве номерами его строки и столбца.
Scilab. После запуска среды scilab на экране появляется основное окно приложения, оно содержит меню, панель инструментов и рабочую область.
1. Решение нелинейных уравнений и систем уравнений
2. Решение задач линейной алгебры
3. Решение задач оптимизации
4. Дифференцирование и интегрирование
5. Задачи обработки экспериментальных данных
6. Решение дифференциальных уравнений и систем уравнений
Признаком того, что система готова к работе, является наличие приглашения. (à_)
После которого располагается активный курсор, эта область называется командной строкой. Ввод команд в командную строку производится с клавиатуры. После ввода необходимо нажать клавишу Enter, это заставит систему выполнить команду и напечатать результат. При этом рабочая область будет прокручиваться вниз, а ранее введенный текст уходит за пределы экрана, чтобы его просмотреть можно:
· Воспользоваться полосой прокрутки справа
· Клавишами листания страниц
Клавиши стрелка вверх и стрелка вниз используется по-другому – если в пустой командной строке нажать клавишу стрелка вверх, то появляется предыдущая введенная команда, если стрелку вниз, то команды выводятся в обратном порядке. Вся информация в рабочей области находится либо в зоне просмотра, либо в зоне редактирования.
В зоне просмотра нельзя ничего исправить или ввести, только выделить и вставить это в зону редактирования. В зоне редактирования, то есть в командной строке, мы можем использовать большинство команд редактирования и управления курсором (перемещение курсора, вставка символов, удаление символов).
Особенности ввода команд. Если команда закачивается «;», то результат ее действия не отображается в командной строке. Если «;» отсутствует, то результат выводится в рабочую область. Если команда не содержит знака «=», то вычисленное значение по умолчанию присваивается системной переменной с именем «ans». Полученное значение можно использовать в последующих вычислениях. Если команда была неверной, то после нажатия клавиши Enter появляется сообщение об ошибке. Текущий документ, содержащий строки ввода-вывода и сообщения об ошибках, называются сессией. Результаты работы сессии можно сохранить в файл.
Основы работы scilab:
1. Текстовый комментарий – строка, начинающаяся с символов //
2. Для выполнений арифметических операций применяются следующие операторы: сложение, вычитание, умножение, деление, возведение в степень…
3. Если вычисляемое выражение слишком длинное, то для продолжения командной строки следует напечатать три и более точек.
Использование переменных: любая переменная сначала определяется. Для этого печатают имя переменной, знак равенства и значение переменной. Знак равенства называют оператором присваивания. Регистр букв к имени различается программой. Длинна имени переменной может содержать до 224-ех символов. Оно не должно совпадать с именами встроенных процедур и функций программы.
Значения, которые присваиваются переменным могут быть не только числовыми, а также арифметическими выражениями, символьными строками или символьными выражениями. Если переменная символьная или строковая, то выражение в правой части берется в одинарные кавычки.
Системные переменные начинаются с символа процента и имеют стандартные значения. При введении вещественных чисел для указания дробной части числа используется точка.
Функции:
Asin, acos, atan – арк- синус, косинус, тангенс.
Кроме встроенных функций используются также функции, определенные пользователем, которые могут являться комбинацией встроенных функций. Если имя переменной, в которые будут записаны результаты вычисления функций, не задано, то значение функции будет присвоено стандартной переменной ans.
Использование массивов и матриц:
Name – имя переменной
Xn – значение первого элемента массива
Xk – значение последнего элемента массива
dX – шаг
[name]=Xn:dX:Xk1
Если параметр dX, то по умолчанию он считается равным единице и каждый следующий элемент массива равен значению предыдущего плюс один. Массив можно использовать в качестве аргумента в выражениях и функциях.
По элементный ввод массива – для этого вводится имя массива и после знака присваивания в квадратных скобках через пробел или запятую перечисляются элементы массива.
Через пробел или запятую вводятся элементы строки. Если нужно ввести элементы столбца, то в качестве разделителя используется «;».
Действия над массивами
При выполнении этих операций действия производятся с каждым элементом массива. Операции сложения и вычитания определены для массивов одинаковой размерности и одинакового размера, то есть при выполнении этих операций производятся действия с элементами массивов, имеющих одинаковые индексы. К массиву также может быть применена функция, при этом каждый элемент массива подвергается действию этой функции. Для массивов используются также специальные функции.
max(M) – вычисляет наибольший элемент в массиве М
min(M) – вычисляет наименьший элемент в массиве М
Построение графиков осуществляется с помощью различных функций с именем plot
Функция plot:
Plot(x,y,[xcap,ycap,caption])
Х – массив значений абсцисс
Y – массив значений ординат
График выводится в отдельном окне и может быть скопирован либо в файл, либо в другую программу Windows. Если мы задаем функцию plot в виде plot(y), то в качестве массива Х берутся номера точек массива y.
Пакет SCILAB для моделирования
SCILAB предусмотрен пакет визуального моделирования динамических систем, то есть из стандартных блоков можно создать модель физического или биологического объекта и проследить как ведет себя эта модель с течением времени. Моделируемые системы могут быть как непрерывными, так и дискретными. Моделью объекта является блок-схема, собранная из стандартных блоков, параметры которых мы можем менять по желанию, а также создавать собственные блоки с нужными свойствами.
Создание новой модели предусматривает выполнений следующих операций:
1. Запуск с пустым окном
2. Открытие одной или более палитр
3. Копирование нужных блоков из палитр в окно
4. Установка параметров блоков нужной величины
5. Соединение входов и выходов блоков
6. Компиляция и запуск модели
7. Переименование и сохранение
Для запуска необходимо выбрать команду «визуальное моделирование Xcos» в меню инструменты. После выполнения этой команды откроются два окна: палитры блоков и безымянный файл, в котором создается модель пользователя и который Вы сохраняете под своим именем. Блоки захватываются мышью и переносятся в окно безымянный файл. Блоки имеют вход и выход, обозначенные стрелочками. Соединения блоков производятся с помощью мыши: делается один щелчок ЛК мыши на выходе одного блока, потом такой же щелчок на входе второго блока. Линии соединения могут быть как прямыми, так и поворачивать под прямым углом (для этого в процессе протягивания линии делается щелчок и поворот в нужном направлении). Для удаления связи ее выделяют щелчком и нажимают кнопку удаления. Линии сигналов черные, а линии активизации красные. Входы и выходы сигналов активации расположены на верхней и нижней стороне блоков. В то время как входы и выходы обычных сигналов установлены на боковых сторонах.
Формирует массив значений необходимый для построения графика, отражающего состояние системы в конкретный момент времени. Следующий блок изображает собой осциллограф. Верхний блок – блок часов активации, он активирует осциллограф, то есть позволяет создать кадр изображения в момент активации.
Системы искусственного интеллекта
Искусственный интеллект – устройство, созданное человеком, решающее задачи, которые могут решать люди. Оно должно быть способно осуществлять восприятие, обучение, анализ, рассуждение, использование значений, планирование действий, логический вывод и т.д.
Этот термин был впервые предложен в 56 году.
Два основные направления в создании искусственного интеллекта:
1. Нейробионика – моделирует искусственным образом процессы, происходящие в мозге человека. На практике это представляет собой разработку элементов подобных нейронам и объединение их в системы – нейросети и нейрокомпьютеры.
2. Информационное – основной целью является не построение тех. Аналога био системы, а моделирование функционирования системы. При этом внутренние механизмы модели могут быть совершенно не похожи на живые аналоги.
Различные подходы к построению систем искусственного интеллекта
1. Логический подход – основан на моделировании рассуждений, базируется на использовании булеввой алгебры – раздел математики, в котором изучаются логические операции над высказываниями.
Предикат – функция, аргументами которой могут быть произвольные объекты из некоторого множества, значениями истина ил ложь. Предикат является расширением понятия высказывание. Множество, на котором предикат принимает только истинные значения называется областью истинности предиката.
Квантор – логическая операция, ограничивающая область истины какого-либо предиката.
Каждая система искусственного интеллекта, построенная на логическом принципе, представляет собой машину доказательства теорем, работу которой можно представить в виде блок-схем. При этом исходные данные задаются в виду аксиом, а правило логического вывода задаются как набор отношений между исходными аксиомами. Каждая такая машина имеет блок генерации цели и система вывода пытается доказать данную цель как теорему. Если цель доказана, то мы получаем цепочку действий (алгоритм) необходимую для решения подобных задач. Для усиления мощности подобных систем используется нечеткая логика, в котором правдивость высказывания может оцениваться в долях единицы. Недостатки: большая трудоемкость метода, так как возможен полный перебор всех вариантов, требуется полная информация о моделируемом объекте. Достоинства: при решении задании мы получаем готовый рецепт решения всех аналогичных задач.
Структурный подход – способ построения искусственного интеллекта путем моделирования структуры человеческого мозга. 1957 г. Френк Розенблатт «Перцептрон» - передающая сеть, состоящая из генераторов двух типов: сенсорные элементы, ассоциативные элементы и реагирующие элементы. Перцептрон должен был передавать сигнал от «глаза», составленного из фотоэлементов, воспринимающих свет в блоки ячеек памяти, которые оценивали величину электрических сигналов, поступающих с фото элементов и соединенных между собой случайным образом. Эта машина могла распознавать буквы. Перед работой перцептрон необходимо было обучить. Обучение состояло в изменении весовых коэффициентов для связей между элементами. Классический метод обучения – обучение с коррекцией ошибки, то есть вес связи не меняется, пока реакция перцептрона остается правильной. При возникновении ошибки весь связи уменьшается. Развитие этого принципа привело к созданию нейронных сетей, у которых может быть много слоев анализирующих элементов. Нейронные сети отличаются друг от друга по строению отдельных нейронов, по типу связей между нейронами и по алгоритмам обучения. Нейронные сети наиболее успешно применяются в задачах распознавания образов, их достоинством является успешное действие при наличии шума. Нейронные сети в медицине используются для диагностики. Нейронная сеть требует предварительного обучения.
Эволюционный подход – использует анализ правил, по которым первоначальная модель может меняться. Первоначальная модель может быть построена с помощью любого из существующих подходов, после чего задаются правила, по которым вносятся изменения в первоначальную модель и из получившихся вариантов отбираются лучшие.
1. Создание первоначальной популяции объектов – популяция создается из видоизмененной первоначальной модели, которая может быть представлена в виде системы уравнений, тогда внесение мутаций – это либо изменение коэффициентов в уравнении, либо изменение количества уравнений, либо изменение отдельных членов уравнения
2. Создание дочерней популяции – выбраковываются «нежизнеспособные» модели, а также оценивается приспособленность полученных моделей и отбираются наилучшие по приспособленности, из которых создается новая популяция.
3. Создание новой популяции
Цикл повторяется до тех пор, пока мы не получим модели, удовлетворяющей нашим требованиям. Основная работа перекладывается с разработчика модели на компьютер, и решив задачу мы не получаем четкого понимания процессов, в моделируемой системе. Мы получаем приемлемый результат даже если он не является оптимальным.
Имитационный подход – данный подход является классическим для кибернетики, в его основе лежит понятие «черного ящика» (англ. Психиатр, кибернетик Уильям Р. Эшби). Черный ящик – устройство, программный модуль или набор данных, информация о внутренней структуре которых отсутствует частично или полностью, но известны спецификации о входных и выходных данных, то есть мы знаем, как объект реагирует на воздействие. При создании модели в этом случае мы добиваемся, чтобы наша модель реагировала точно так же. Выделяют белый, серый и черный ящики по степени информированности. При этом подходе внутренняя структура модели не должна повторять внутреннюю структуру объекта.
1. Исследователь вносит гипотезу о структуре ящика; Y = А1Х + A0
2. Задание значений коэффициентов; A0 и А1
3. Проверка адекватности реакций модели
Основным недостатком является низкая информационная способность большинства полученных моделей.
Экспертные системы – компьютерная программа, способная заменить специалиста-эксперта в разрешении проблемной ситуации. ЭС появились в 70-хх годах прошлого века и являются применением систем искусственного интеллекта для решения конкретных задач. Они отличаются от простых систем обработки данных тем, что в них может использоваться символьный способ представления, символьный вывод и эвристический поиск решения (без известного алгоритма решения).
Структура ЭС:
1. Интерфейс пользователя – программа, позволяющая пользователю общаться с системой на привычном языке профессиональных терминов
2. Пользователь – специалист, обученный работе с ЭС
3. Интеллектуальный редактор базы данных – программа, позволяющая вносить сведения в базу знаний без нарушения ее структуры
4. Эксперт – специалист, хорошо изучивший проблемную область
5. Инженер по знаниям – специалист по выявлению и структурированию знания
6. Рабочая (оперативная) память
7. База знаний – включает в себя набор фактов и сведений (статистических) о предметной области, а также правила анализа и вывода для хранящейся информации
8. Механизм вывода – набор алгоритмов и правил, полученных после обучения системы искусственного интеллекта для решения задач в проблемной области
9. Подсистема объяснений
ЭС создается при помощи трех групп людей: эксперты, инженеры по знаниям, программисты, реализующие программы, входящие в ЭС.
Режимы функционирования ЭС:
1. Режим ввода знаний – эксперт с помощью инженера по знаниям вводит сведения из предметной области в базу знаний посредством редактора базы знаний. Ввод знаний бывает прямой и статистический.
2. Режим консультации – пользователь ведет диалог, сообщая ЭС сведения о текущей задачи и получая рекомендации от ЭС.
ЭС MYCIN 1974 г. – система для диагностики бактериальных инфекций.
Правила диагностики для подобных систем имеют вид, если (Х), то (Y1) – Р?, (Y2) – Р? …
Применяя подобные правила мы получаем итоговую вероятность для каждого возможного диагноза Y при наличии конкретных симптомов Х, после чего система отбирает наиболее вероятные диагнозы.
Каждая ЭС, как правило, посвящена одной узкой задаче. Российские ЭС:
1. Нефрекс
2. Репрокод
3. Диакомс – онкологические заболевания глаз
4. ES 4.0 – диагностика заболевания молочных желез, щитовидной железы
Медицинские информационные системы
Информационные системы – взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в целях решения поставленной задачи.
МИС - -“- в целях решения задач из области медицины и организации работы медицинских учреждений.
История информационных систем
Первые ИС появились в 50-ые годы прошлого века, предназначались для обработки щитов и расчета зарплат, реализовывались на электромеханических бухгалтерских счетных машинах.
60-ые гг. – обрабатывают информацию, которая классифицируется и запрашивается по многим параметрам – реализованы на больших ЭВМ, предназначены для решения широкого круга задач (планирование трат, логистические задачи, статистических анализ данных).
70-80-е гг. – ИС используются в качестве средств управленческого контроля, поддерживающего и ускоряющего процесс принятия решений. Реализованы на базе больших и малых ЭВМ, действующих по диной схеме.
ИС становятся стратегическим источником информации и используются на всех уровнях в организациях любого профиля (гос., военных, промышленных и т.д.).
ИС стали обучаемыми и включают в себя подсистемы принятия решений, как правило, имеют доступ к мировой информационной сети.
Классификация МИС по решаемым задачам:
1. Информационно-справочные системы
2. Консультативно-диагностические системы
3. Приборно-компьютерные системы – системы для информационной поддержки и автоматизации диагностического и лечебного процесса, осуществляемых при непосредственном контакте в организмом больного.
4. Автоматизированные рабочие места специалистов, позволяющие осуществить информационную поддержку при принятии диагностических и тактических врачебных решений
Электронная история болезни
Часто под МИС понимают электронную историю болезни (ЭИБ).
01.01.2008 вступил в силу нац. стандарт «ЭИБ. Общие положения». Требования к таким системам определяет ГОСТ.
Нац. стандарт базируется на международном стандарте HL7. Этот стандарт описывает процедуры и механизмы обмена, управления и интеграции ЭИБ.
Термины и определения стандарта:
ЭИБ – ИС, предназначенная для ведения, хранения, поиска и выдачи по запросам персональных мед записей.
Персональная медицинская запись – любая запись, сделанная конкретным мед работником и сохраненная на электронном носителе.
ЭПМЗ – любая персональная мед запись, сохраненная на электронном носителе.
Электронный мед архив – хранилище данных содержащие ЭПМЗ, а также наборы программ, используемых МИС.
Классификация систем (ЭИБ и ЭПМЗ) – разделяются на два класса: индивидуальные и коллективные системы.
Индивидуальные системы – являются лишь тех средствами для подготовки традиционных мед записей на бумажном носителе, которые подписываются и используются в соответствии с правилами работы с мед документами. Хранящиеся в индивидуальных системах и электронных архивах документы не имеют самостоятельного статуса и не являются мед документами. Вся ответственность за содержание и жизненный цикл документа возлагается на его автора.
Коллективные системы ЭПМЗ – в них ЭПМЗ отчуждаются от автора, то есть могут быть извлечены из архива другим мед работником и использованы в качестве официального мед документа. Поэтому в коллективных системах существуют доп. требования, регламентирующие отчуждение ЭПМЗ от автора и придание ей статуса мед документа.
Требования к структуре ЭПМЗ в коллективных системах:
ОЭ – обязательный элемент
ЭПМЗ включает в себя след элементы:
1. идентификатор пациента – ОЭ однозначно определяющий к какому пациенту относится данное ЭПМЗ.
2. Идентификатор данной ЭПМЗ – ОЭ, позволяющий однозначно идентифицировать ЭПМЗ в архиве (указывается в бумажных копиях и передается по электронным каналам связей).
3. Дата и время
4. Номер истории болезни
5. Идентификатор лица, создавшего запись – ОЭ, позволяющий однозначно определить, кто создал данную запись.
6. Текст ЭПМЗ – не ОЭ, представляющий собой мед содержание данной ЭПМЗ.
7. Прикрепленные файлы – не ОЭ, содержащие доп инфу и имющие стандартные форматы
8. Формализованные данные, прикрепленные к ЭПМЗ. Позволят проводить поиск и фильтрацию данных по разным параметрам. Осуществлять корректный перевод на другие языки, проводить стат обработку и создавать отчеты
9. Идентификатор автора ЭПМЗ – ОЭ, позволяющие однозначно определить, кто является автором данной мед записи и несет ответственность за ее содержание. Автором считается именно лицо, несущее ответственность за содержание, а не лица, участвовавшие в создании ЭПМЗ.
10. Дата и время подписания ЭПМЗ – ОЭ, указывающий с какого момента ЭПМЗ считается законченной и приобретает статус официального мед документа.
11. Дайджест – элемент, полученный методом шифрования содержимого ЭПМЗ
Жизненный цикл ЭПМЗ:
1. Создание
2. Ведение
3. Подписание
4. Хранение
5. Уничтожение
Подписание ЭПМЗ является тех процедурой. Выполнив ее, автор принимает на себя всю ответственность за содержание ЭПМЗ. Процедура подписания должна быть активной и осознанной и сопровождаться действиями, позволяющими произвести персонификацию мед сотрудника: ввод пароля, подключение электронного идентифицирующего устройства.
Интерфейс связи – обеспечивает информационный обмен ключа с компьютером, соответствует порту компьютера, к которому может быть подключен ключ
Процессор – реализует функцию выполнения кода, хранящегося в памяти ключа
ОЗУ – память, предназначенная для хранения переменных при выполнении кода и организации обмена данными
Энергонезависимая память – предназначена для хранения программного кода и данных, который необходимо скрыть от злоумышленника
Часы реального времени – служат для выполнения доп. функций электронного ключа (создание временных лицензий, ограничение доступа по времени, фиксация времени при создании электронной подписи)
Элемент питания – долго действующая батарейка (ториевая)
Функции АРМ
Автоматизированное рабочее место врача – программно-технический комплекс для автоматизации профессиональной деятельности специалиста
АРМ объединяет программно-аппаратные средства в один комплекс (мед прибор + компьютер), предоставляет возможность ввода и получения информации в нужном виде
Функции: сайт врача, БД прецедентов, система поддержки врачебных решений, обработка визуальных образов, электронный документооборот
АРМ иридолога (иридодиагностика – анализ состояния радужной оболочки глаза и диагностика по ней)
Состав АРМ:
ПО: экспертная система, графический редактор, атласы иридолога
Оборудование: компьютер, цифровая камера
Доп. компоненты: программы-утилиты, видеокамера, цветной TV-приемник, видеомагнитофон, доп. монитор, сканер
Этапы диагностики:
1. Ввод и обработка изображений (графический редактор)
2. Постановка диагноза (ЭС и атласы)
3. Планирование оздоровительных мероприятий (программы-утилиты)
Компьютерные системы поддержки врачебных решений – включают в себя базы мед данных и комплекс программ для решения диагностических, прогностических и лечебных задач. При этом используются след информационные технологии:
1. Теория принятия решения
2. Метод вывода по прецедентам
3. Теория распознавания образов
Вывод, основанный на прецедентах – метод принятия решений, в котором используются знания о предыдущих ситуациях или случаях (встречавшихся ранее проблемах или типичных случаях, а также принятых тогда решениях).
Прецеденты хранятся в БД, при этом каждый прецедент описан по определённому алгоритму
Структура прецедента:
1. Описание случая
2. Описание решения
3. Результат применения решения (исход)
Схема принятия решений по прецедентам
Вывод на основе прецедентов является методом принятия решений, моделирующим человеческие рассуждения. Он использует знания о предыдущих случаях (прецедентах) и ранее принятых решениях.
Этапы:
1. При поступлении новой проблемы (текущий случай) в БД находится аналогичный похожий случай или несколько случаев (отобранные прецеденты)
2. Отобранные прецеденты адаптируются к текущему случаю и на основании этой адаптации принимается решение сходное с решениями прецедентов (или альтернативное решение)
3. После наблюдений, проведенных за пациентом, и получения исхода заболевания текущий случай анализируется и может быть внесен в БД (сохраненный прецедент) с указанием метода лечения и полученного исхода
Такой метод позволяет создать самообучающуюся систему – чем больше прецедентов, тем выше вероятность найти самый подходящий прецедент и выше качество принимаемого решения.
При реализации работы с базой прецедентов выбирается многоуровневое решение, то есть программа, работающая с базой имеет две части: оболочка и анализатор базы.
Оболочка (презентационный слой программы) – уровень системы, реализующий взаимодействие с конечным пользователем. С ее помощью врач получает доступ к данным, пользуясь привычными для себя терминами (пациент, показатель, заболевание, лечение, исход).
Второй уровень – анализатор (прикладной слой) – при работе с данными использует понятия «класс», «объект», «признак» и выполняет операции анализа данных, классификацию, оценку, прогнозирование и т.д. Подобным образом организованы многие системы поддержки врачебных решений.
В основе подходов к отбору прецедентов – оценка схожести.
Введение метрики – «мера близости» (евклидово расстояние).
Введение «классов схожести».
Способы построения классов:
1. На основе экспертного знания
2. Специально разработанных обучающих выборок
3. Или путем кластеризации базы прецедентов
Для того, чтобы определить границы классов схожести необходимо составить перечень признаков класса и задать границы признаков класса.
ГЕНРЕГ – медико-генетический реестр
Задачи:
1. Формирование БД, включающей всю информацию о семьях с наследственной патологией
2. Организация и модификация данных
3. Организация интерфейса (оболочки), позволяющего использовать естественный язык
4. Вычисляет категории родства между членами родословной
5. Рассчитывает риски для членов родословной
6. Проводит статистический анализ при массовых исследованиях
7. Контролирует сроки периодических осмотров и формирует списки диспансеризации
ИНТЕРИС – информационная система отделения реанимации и интенсивной терапии
Медицинские приборно-компьютерные системы (МПКС)
Основное отличие этого класса систем – относятся к мед информационным системам базового уровня, работа ведется в условиях непосредственного контакта с пациентом в режиме реального времени. Они являются сложными программно-аппаратными комплексами. Для их работы необходимо помимо вычислительной техники использовать специальные мед приборы и средства связи.
Три основные составляющие МПКС:
1. Медицинское обеспечение – включает в себя способы реализации мед задач (наборы, используемых методик, измеряемые физиологические параметры и методы их измерения, определение способов и границ воздействия на пациентов)
2. Программное обеспечение – математические методы обработки информации, алгоритмы и программы, управляющие функционированием системы
3. Аппаратное обеспечение – способы реализации технической части системы (средства получения медико-биологической информации, средства осуществления лечебных воздействий, средства лечебной техники)
Области применения МПКС:
1. Мед диагностика
2. Системы для проведения мониторинга – при непрерывном наблюдении за больными в палатах интенсивной терапии
3. Для выполнения мониторной работы используют мониторные МПКС, они обладают средствами экспресс-анализа в реальном времени. Системы управления лечебным процессом – системы интенсивной терапии, системы с биологической обратной связью, а также искусственные органы. Системы, управляющие лечебным процессом могут предоставлять пациенту информацию о его состоянии и регулировать действия пациента по корректировки этого состояния.
4. Телемедицина – комплекс современных лечебно-диагностических методик для дистанционного управления мед информацией. Телемедицина первоначально возникла с развитием космических полетов, когда передавались данные о жизнедеятельности космонавтов и данные о необходимых лечебных действиях.
Области реализации телемедицинских технологий:
1. Обслуживание групп населения, имеющих ограниченный доступ к мед службам
2. Система диагностических центров, связанная дистанционно с лечащими врачами в различных лечебных учреждениях
3. Ситуация экстренной помощи, когда требуется консультация специалиста или проведение дистанционной хирургической операции с помощью специальных систем манипуляторов с дистанционной связью
4. Дистанционное мед образование
Дискретизация сигналов
При дискретизации во времени непрерывный аналоговый сигнал заменяется последовательностью отсчетов, величина которых равно значения сигнала в данный момент времени. По таким отсчетам можно восстановить исходную непрерывную функцию с заданной точностью. Возможность точного воспроизведения зависит от времени между отсчетами.
В.А. Котельников – советский ученый главный разработчик систем радиотехники.
Теорема Котельникова впервые обосновала возможность цифровой передачи информации и стала одной из основ современной теории информации. Известно, что любое сложное колебание (сигнал) можно разложить на гармонические колебания с разными частотами (анализ Фурье).
Теорема Котельникова: если измеряемая величина непрерывно изменяется во времени и ее можно представить в виде суммы колебаний с различными частотами, то такую величину можно представить с помощью дискретных отсчетов, взятых через интервалы времени Δt равные или меньшие 1/2*Fmax
Fmax – наибольшее из частот
Теорема Котельникова лежит в основе работы всех современных аналогово-цифровых преобразователей (АЦП).
АЦП – приборы, предназначенные для преобразования аналоговых сигналов в цифровую форму. В медицине АЦП – это обязательная часть программно-аппаратных комплексов регистрации и анализа кардиограмм, энцефалограмм и т.д. АЦП может изготавливаться либо в виде отдельной микросхемы, устанавливаемой в прибор или в виде отдельной платы для компьютера. Каждая реализация АЦП имеет свои преимущества: плата, устанавливаемая в компьютер, может принимать широкий диапазон сигналов, то есть работать с разными приборами. В то время как микросхема АЦП внутри измерительного прибора хорошо приспособлена к данному прибору, но работает только с ним.
Характеристики АЦП:
1. Частота дискретизации – количество отсчетов за единицу времени
2. Разрядность – количество дискретных значений, которые преобразователь дает на выходе. Измеряется в битах
Например, АЦП, выдающий 256 дискретных значений, имеет разрядность 8 бит. Потому что 28 = 256. Разрядность выбирается в зависимости от величины входного сигнала и в зависимости от точности его измерения.
(10-0) /28=10/256=0,039 вольт
Компьютерные вирусы
Вирусами называются программы, способные к воспроизведению своего кода и обеспечению его последующего исполнения.
Теория самовоспроизводящихся автоматов (Джон фон Нейман). Прочитал серию лекций «Теория и организация сложных автоматов». Теория создания самовоспроизводящихся программ развивается с 1948 г. Первоначально такие программы были игровыми и создавались учеными ради развлечения (программа Дарвин). Далее подобные программы стали выходить за пределы научных лабораторий и заражать компьютеры, входящие в локальные сети. Первые антивирусные программы появились в 1984 г. Переломным годом стал 1987. Главным путем распространения вирусов в то время, было распространение с дискетами. Первая эпидемия 1987 г. «Brain» для DOS. Октябрь 1987 г. – вирус Jerusalem уничтожал файлы компьютера при их запуске в пятницу 13-ого. Эпидемия вируса CIH (он же «Чернобль»), автор вируса студент Чень Инхао. УК РФ 28. Преступления в сфере компьютерной информации (срок до 7-ми лет). В настоящее время вирусописательство – это отрасль интеллектуальных технологий, используемая в коммерческих, государственных, военных и криминальных интересах. Такие работы выполняются как крупными организациями, так и группами программистов, собранными с заданной целью.
Не существует единой классификации вирусов, встречаются следующие виды классификаций:
1. По поражаемым объектам
2. По поражаемым операционным системам и платформам
3. По технологиям, используемым вирусом
4. По языку, на котором написан вирус
5. По доп. вредоносной функциональности
Поэтому чаще всего вирус разбиваются на условные группы, согласно особенностям их жизненного цикла.
Классические вирусы – начинают свою работу после выполнения пользователем определенных действий (загрузка, исполняемого файла, распаковка архива). Как правило, эти вирусы не способны самостоятельно распространяться по сети и переносятся с помощью флешек и дисков. Вирусы используют следующие технологии:
· полиморфные вирусы – их программный код постоянно меняется, что защищает их от антивирусных программ. Обезвредить эти вирусы можно только с использованием про активных методов, в которых анализируются особенности поведения, присущие каждому виду вирусов. 1990 г. Chameleon.
· Стелс-вирусы: 1987 г. Brain. При попытке чтения зараженного сектора этот вирус подставляет читающей программе копию незараженного оригинала диска, и программа считает, что вируса нет.
Черви – разновидность самовоспроизводящихся компьютерных программ, способных к саморазмножению в компьютерных сетях не санкционированному пользователю. Черви используют разные пути распространения, некоторые требуют определенных действий пользователя (открытие инфицированного письма), другие распространяются автономно, выбирая объект заражения в автоматическом режиме. Встречаются черви, использующие комбинированную стратегию.
· Сетевые черви
· Почтовые черви
· IRC-черви
· IM-черви
Первый массовый сетевой червь был создан в 1988 г. Робертом Моррисом. Черви не всегда выполняют вредоносные действия, часто их используют для в комплексе с другими вирусами, например, с троянами.
Троянские кони – вредоносная программа, проникающая в компьютер под видом безвредной. Она не имеет своего собственного механизма распространения и очень проста в написании. Трояны могут выполнять следующие функции: мешать работе пользователя, шпионить за пользователем, использовать ресурсы компьютера для незаконной деятельности.
Жизненный цикл вируса:
1. Черви – проникновение в системы, активация, поиск жертв, подготовка копий, распространение копий
2. Троян – проникновение на компьютер (благодаря действиям пользователя или с червем), активация, выполнение заложенных вредоносных функций
Хакерские утилиты – проникают на компьютер с заранее запрограммированными задачами (взлом защиты и предоставление удаленного доступа к ресурсам компьютера) или используются для автоматизации создания других вирусов и червей.
Моделирование эпидемий
Даниил Бернулли.
С этого времени возникли два основных направления в моделировании эпидемий:
1. Аналитический подход – учитывает статистические данные и показатели и составляет прогностическую модель эпидемии
2. Путь эмпирических наблюдений – в этом случае исследуются пути распространения инфекции и моделируются способы перекрывания этих путей
В течении 20-ого века аналитическое направление развивалось очень интенсивно, и к нашему времени были созданы эффективные модели распространения эпидемий.
ЭПИДДИНАМИКА – с 60-хх гг. до настоящего времени (Бароян и Рвачев). Основана на методе аналогии в отображении эпидемического процесса, то есть процесс переноса возбудителей инфекции моделируется с помощью методов, разработанных математической физикой для описания переноса материи, энергии и импульса. Модель при этом представляет собой систему дифференциальных уравнений в частных производных.
Простая эпидемическая модель. В нашем модели мы рассмотрим три группы населения: уязвимые (S), зараженные (I), неподверженные заражению (R).
Β – средняя постоянная скорость заражения.
i = I/N – удельное количество информации
s = S/N – удельное количество восприимчивых к заражению
s + i = 1
s = 1-i
Тогда можно составить дифференциальное уравнение скорости изменения числа, инфицированных за интервал времени dt.
di/dt = β (1-i)i
Чем больше значения s, i, тем больше вероятность передачи инфекции.
Проинтегрировав это уравнение, мы получаем логистическое уравнение, описывающее развитие эпидемии. Согласно этому графику существует три этапа развития эпидемии:
1. Занос инфекции
2. Экспоненциальный рост числа зараженных
3. Полное развитие эпидемии
В графике не учтена возможность приобретения иммунитета.
SIR модель: S+I+R=N
ПЛАН
Дата добавления: 2014-11-24; просмотров: 43 | Поможем написать вашу работу | Нарушение авторских прав |