Читайте также:
|
Задача умножения матрицы на вектор определяется соотношениями
 .
.
Тем самым, получение результирующего вектора  предполагает повторения
предполагает повторения 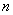 однотипных операций по умножению строк матрицы
однотипных операций по умножению строк матрицы  и вектора
и вектора  . Получение каждой такой операции включает поэлементное умножение элементов строки матрицы и вектора и последующее суммирование полученных произведений. Общее количество необходимых скалярных операций оценивается величиной
. Получение каждой такой операции включает поэлементное умножение элементов строки матрицы и вектора и последующее суммирование полученных произведений. Общее количество необходимых скалярных операций оценивается величиной
 .
.
Как следует из выполняемых действий при умножении матрицы и вектора, параллельные способы решения задачи могут быть получены на основе параллельных алгоритмов суммирования (см. параграф 4.1). В данном разделе анализ способов распараллеливания будет дополнен рассмотрением вопросов организации параллельных вычислений в зависимости от количества доступных для использования процессоров. Кроме того, на примере задачи умножения матрицы на вектор будут обращено внимание на необходимость выбора наиболее подходящей топологии вычислительной системы (существующих коммуникационных каналов между процессорами) для снижения затрат для организации межпроцессорного взаимодействия.
Достижение максимально возможного быстродействия ( )
)
1. Выбор параллельного способа вычислений. Выполним анализ информационных зависимостей в алгоритме умножения матрицы на вектор для выбора возможных способов распараллеливания. Как можно заметить
- выполняемые при проведении вычислений операции умножения отдельных строк матрицы на вектор являются независимыми и могут быть выполнены параллельно;
- умножение каждой строки на вектор включает независимые операции поэлементного умножения и тоже могут быть выполнены параллельно;
- суммирование получаемых произведений в каждой операции умножения строки матрицы на вектор могут быть выполнены по одному из ранее рассмотренных вариантов алгоритма суммирования (последовательный алгоритм, обычная и модифицированная каскадные схемы).
Таким образом, максимально необходимое количество процессоров определяется величиной
.
Использование такого количества процессоров может быть представлено следующим образом. Множество процессоров 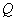 разбивается на групп
разбивается на групп
 ,
,
каждая из которых представляет набор процессоров для выполнения операции умножения отдельной строки матрицы на вектор. В начале вычислений на каждый процессор группы пересылаются элемент строки матрицы и соответствующий элемент вектора . Далее каждый процессор выполняет операцию умножения. Последующие затем вычисления выполняются по каскадной схеме суммирования. Для иллюстрации на рис. 4.5 приведена вычислительная схема для процессоров группы  при размерности матрицы
при размерности матрицы  .
.

Рис. 4.5. Вычислительная схема операции умножения строки матрицы на вектор
2. Оценка показателей эффективности алгоритма. Время выполнения параллельного алгоритма при использовании процессоров определяется временем выполнения параллельной операции умножения и временем выполнения каскадной схемы
 .
.
Как результат, показатели эффективности алгоритма определяются следующими соотношениями:
,  ,
,
 .
.
3. Выбор топологии вычислительной системы. Для рассматриваемой задачи умножения матрицы на вектор наиболее подходящими топологиями являются структуры, в которых обеспечивается быстрая передача данных (пути единичной длины) в каскадной схеме суммирования (см. рис. 4.5). Таковыми топологиями являются структура с полной системой связей (полный граф) и гиперкуб. Другие топологии приводят к возрастанию коммуникационного времени из-за удлинения маршрутов передачи данных. Так, при линейном упорядочивании процессоров с системой связей только с ближайшими соседями слева и справа (линейка или кольцо) для каскадной схемы длина пути передачи каждой получаемой частичной суммы на итерации 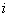 ,
, 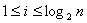 , является равной
, является равной  . Если принять, что передача данных по маршруту длины
. Если принять, что передача данных по маршруту длины  в топологиях с линейной структурой требует выполнения операций передачи данных, общее количество параллельных операций (суммарной длительности путей) передачи данных определяется величиной
в топологиях с линейной структурой требует выполнения операций передачи данных, общее количество параллельных операций (суммарной длительности путей) передачи данных определяется величиной

(без учета передач данных для начальной загрузки процессоров).
Применение вычислительной системы с топологией в виде прямоугольной двумерной решетки размера  приводит к простой и наглядной интерпретации выполняемых вычислений (структура сети соответствует структуре обрабатываемых данных). Для такой топологии строки матрицы наиболее целесообразно разместить по горизонталям решетки; в этом случае элементы вектора должны быть разосланы по вертикалям вычислительной системы. Выполнение вычислений при таком размещении данных может осуществляться параллельно по строкам решетки; как результат, общее количество передач данных совпадает с результатами для линейки (
приводит к простой и наглядной интерпретации выполняемых вычислений (структура сети соответствует структуре обрабатываемых данных). Для такой топологии строки матрицы наиболее целесообразно разместить по горизонталям решетки; в этом случае элементы вектора должны быть разосланы по вертикалям вычислительной системы. Выполнение вычислений при таком размещении данных может осуществляться параллельно по строкам решетки; как результат, общее количество передач данных совпадает с результатами для линейки ( ).
).
Коммуникационные действия, выполняемые при решении поставленной задачи, состоят в передаче данных между парами процессоров МВС. Подробный анализ длительности реализации таких операций проведен в п. 3.3.
4. Рекомендации по реализации параллельного алгоритма. При реализации параллельного алгоритма целесообразно выделить начальный этап по загрузке используемых процессоров исходными данными. Наиболее просто такая инициализация обеспечивается при топологии вычислительной системы с топологией в виде полного графа (загрузка обеспечивается при помощи одной параллельной операции пересылки данных). При организации множества процессоров в виде гиперкуба может оказаться полезной двухуровневое управление процессом начальной загрузки, при которой центральный управляющий процессор обеспечивает рассылку строк матрицы и вектора к управляющим процессорам процессорных групп ,  , которые, в свою очередь, рассылают элементы строк матрицы и вектора по исполнительным процессорам. Для топологий в виде линейки или кольца требуется
, которые, в свою очередь, рассылают элементы строк матрицы и вектора по исполнительным процессорам. Для топологий в виде линейки или кольца требуется  последовательных операций передачи данных с последовательно убывающим объемом пересылаемых данных от
последовательных операций передачи данных с последовательно убывающим объемом пересылаемых данных от  до
до  элементов.
элементов.
Использование параллелизма среднего уровня ( )
)
1. Выбор параллельного способа вычислений. При уменьшении доступного количества используемых процессоров (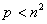 ) обычная каскадная схема суммирования при выполнении операций умножения строк матрицы на вектор становится не применимой. Для простоты изложения материала положим
) обычная каскадная схема суммирования при выполнении операций умножения строк матрицы на вектор становится не применимой. Для простоты изложения материала положим  и воспользуется модифицированной каскадной схемой. Начальная нагрузка каждого процессора в этом случае увеличивается и процессор загружается (
и воспользуется модифицированной каскадной схемой. Начальная нагрузка каждого процессора в этом случае увеличивается и процессор загружается ( ) частями строк матрицы и вектора . Время выполнения операции умножения матрицы на вектор может быть оценено как величина
) частями строк матрицы и вектора . Время выполнения операции умножения матрицы на вектор может быть оценено как величина

 .
.
При использовании количества процессоров, необходимого для реализации модифицированной каскадной схемы, т.е. при  , данное выражение дает оценку времени исполнения
, данное выражение дает оценку времени исполнения  (при
(при  ).
).
При количестве процессоров  , когда время выполнения алгоритма оценивается как
, когда время выполнения алгоритма оценивается как  , может быть предложена новая схема параллельного выполнения вычислений, при которой для каждой итерации каскадного суммирования используются неперекрывающиеся наборы процессоров. При таком походе имеющегося количества процессоров оказывается достаточным для реализации только одной операции умножения строки матрицы и вектора . Кроме того, при выполнении очередной итерации каскадного суммирования процессоры, ответственные за исполнение всех предшествующих итераций, являются свободными. Однако этот недостаток предлагаемого подхода можно обратить в достоинство, задействовав простаивающие процессоры для обработки следующих строк матрицы . В результате может быть сформирована следующая схема конвейерного выполнения умножения матрицы и вектора:
, может быть предложена новая схема параллельного выполнения вычислений, при которой для каждой итерации каскадного суммирования используются неперекрывающиеся наборы процессоров. При таком походе имеющегося количества процессоров оказывается достаточным для реализации только одной операции умножения строки матрицы и вектора . Кроме того, при выполнении очередной итерации каскадного суммирования процессоры, ответственные за исполнение всех предшествующих итераций, являются свободными. Однако этот недостаток предлагаемого подхода можно обратить в достоинство, задействовав простаивающие процессоры для обработки следующих строк матрицы . В результате может быть сформирована следующая схема конвейерного выполнения умножения матрицы и вектора:
- множество процессоров разбивается на непересекающиеся процессорные группы

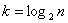 ,
,
при этом группа ,  , состоит из
, состоит из  процессоров и используется для выполнения итерации каскадного алгоритма (группа
процессоров и используется для выполнения итерации каскадного алгоритма (группа  применяется для реализации поэлементного умножения); общее количество процессоров
применяется для реализации поэлементного умножения); общее количество процессоров  ;
;
- инициализация вычислений состоит в поэлементной загрузке процессоров группы значениями 1 строки матрицы и вектора ; после начальной загрузки выполняется параллельная операция поэлементного умножения и последующей реализации обычной каскадной схемы суммирования;
- при выполнении вычислений каждый раз после завершения операции поэлементного умножения осуществляется загрузка процессоров группы элементами очередной строки матрицы и инициируется процесс вычислений для вновь загруженных данных.
В результате применения описанного алгоритма множество процессоров реализует конвейер для выполнения операции умножения строки матрицы на вектор. На подобном конвейере одновременно могут находиться несколько отдельных строк матрицы на разных стадиях обработки. Так, например, после поэлементного умножения элементов первой строки и вектора процессоры группы  будут выполнять первую итерацию каскадного алгоритма для первой строки матрицы, а процессоры группы будут исполнять поэлементное умножение значений второй строки матрицы и т.д. Для иллюстрации на рис. 4.6 приведена ситуация процесса вычислений после 2 итераций конвейера при .
будут выполнять первую итерацию каскадного алгоритма для первой строки матрицы, а процессоры группы будут исполнять поэлементное умножение значений второй строки матрицы и т.д. Для иллюстрации на рис. 4.6 приведена ситуация процесса вычислений после 2 итераций конвейера при .

Рис. 4.6. Состояние конвейера для операции умножения строки матрицы на вектор после выполнения 2 итераций
2. Оценка показателей эффективности алгоритма. Умножение первой строки на вектор в соответствии с каскадной схемой будет завершено, как и обычно, после выполнения ( ) параллельных операций. Для других же строк – в соответствии с конвейерной схемой организации вычислений - появление результатов умножения каждой очередной строки будет происходить после завершения каждой последующей итерации конвейера. Как результат, общее время выполнения операции умножения матрицы на вектор может быть выражено величиной
) параллельных операций. Для других же строк – в соответствии с конвейерной схемой организации вычислений - появление результатов умножения каждой очередной строки будет происходить после завершения каждой последующей итерации конвейера. Как результат, общее время выполнения операции умножения матрицы на вектор может быть выражено величиной
 .
.
Данная оценка является несколько большей, чем время выполнения параллельного алгоритма, описанного в предыдущем пункте ( ), однако вновь предлагаемый способ требует меньшего количества передаваемых данных (вектор пересылается только однократно). Кроме того, использование конвейерной схемы приводит к более раннему появлению части результатов вычислений (что может быть полезным в ряде ситуаций обработки данных).
), однако вновь предлагаемый способ требует меньшего количества передаваемых данных (вектор пересылается только однократно). Кроме того, использование конвейерной схемы приводит к более раннему появлению части результатов вычислений (что может быть полезным в ряде ситуаций обработки данных).
Как результат, показатели эффективности алгоритма определяются соотношениями следующего вида:
,  ,
,
 .
.
3. Выбор топологии вычислительной системы. Целесообразная топология вычислительной системы полностью определяется вычислительной схемой – это полное бинарное дерево высотой . Количество передач данных при такой топологии сети определяется общим количеством итераций, выполняемых конвейером, т.е.
 .
.
Инициализация вычислений начинается с листьев дерева, результаты суммирования накапливаются в корневом процессоре.
Анализ трудоемкости выполняемых коммуникационных действий для вычислительных систем с другими топологиями межпроцессорных связей предполагается осуществить в качестве самостоятельного задания (см. также п. 3.4).
Организация параллельных вычислений при 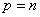
1. Выбор параллельного способа вычислений. При использовании процессоров для умножения матрицы на вектор может быть использован ранее уже рассмотренный в пособии параллельный алгоритм построчного умножения, при котором строки матрицы распределяются по процессорам построчно и каждый процессор реализует операцию умножения какой-либо отдельной строки матрицы на вектор . Другой возможный способ организации параллельных вычислений может состоять в построении конвейерной схемы для операции умножения строки матрицы на вектор (скалярного произведения векторов) путем расположения всех имеющихся процессоров в виде линейной последовательности (линейки).
Подобная схема вычислений может быть определена следующим образом. Представим множество процессоров в виде линейной последовательности (см. рис. 4.7):
 ;
;
каждый процессор  ,
,  , используется для умножения элементов
, используется для умножения элементов 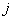 столбца матрицы и элемента вектора . Выполнение вычислений на каждом процессоре , , состоит в следующем:
столбца матрицы и элемента вектора . Выполнение вычислений на каждом процессоре , , состоит в следующем:
- запрашивается очередной элемент столбца матрицы;
- выполняется умножение элементов  и
и  ;
;
- запрашивается результат вычислений 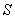 предшествующего процессора;
предшествующего процессора;
- выполняется сложение значений  ;
;
- полученный результат пересылается следующему процессору.

Рис. 4.7. Состояние линейного конвейера для операции умножения строки матрицы на вектор после выполнения двух итераций
При инициализации описанной схемы необходимо выполнить ряд дополнительных действий:
- при выполнении первой итерации каждый процессор дополнительно запрашивает элемент вектора ;
- для синхронизации вычислений (при выполнении очередной итерации схемы запрашивается результат вычисления предшествующего процессора) на этапе инициализации процессор , , выполняет ( ) цикл ожидания.
) цикл ожидания.
Кроме того, для однородности описанной схемы для первого процессора  , у которого нет предшествующего процессора, целесообразно ввести пустую операцию сложения (
, у которого нет предшествующего процессора, целесообразно ввести пустую операцию сложения ( ).
).
Для иллюстрации на рис. 4.7 показано состояние процесса вычислений после второй итерации конвейера при  .
.
2. Оценка показателей эффективности алгоритма. Умножение первой строки на вектор в соответствии с описанной конвейерной схемой будет завершено после выполнения ( ) параллельных операций. Результат умножения следующих строк будет происходить после завершения каждой очередной итерации конвейера (напомним, итерация каждого процессора включает выполнение операций умножения и сложения). Как результат, общее время выполнения операции умножения матрицы на вектор может быть выражено соотношением:
) параллельных операций. Результат умножения следующих строк будет происходить после завершения каждой очередной итерации конвейера (напомним, итерация каждого процессора включает выполнение операций умножения и сложения). Как результат, общее время выполнения операции умножения матрицы на вектор может быть выражено соотношением:
 .
.
Данная оценка также является большей, чем минимально возможное время  выполнения параллельного алгоритма при
выполнения параллельного алгоритма при  . Полезность использования конвейерной вычислительной схемы состоит, как отмечалось в предыдущем пункте, в уменьшении количества передаваемых данных и в более раннем появлении части результатов вычислений.
. Полезность использования конвейерной вычислительной схемы состоит, как отмечалось в предыдущем пункте, в уменьшении количества передаваемых данных и в более раннем появлении части результатов вычислений.
Показатели эффективности данной вычислительной схемы определяются соотношениями:
 ,
,  ,
,
 .
.
3. Выбор топологии вычислительной системы. Необходимая топология вычислительной системы для выполнения описанного алгоритма однозначно определяется предлагаемой вычислительной схемой – это линейно упорядоченное множество процессоров (линейка).
Использование ограниченного набора процессоров ( )
)
1. Выбор параллельного способа вычислений. При уменьшении количества процессоров до величины параллельная вычислительная схема умножения матрицы на вектор может быть получена в результате адаптации алгоритма построчного умножения. В этом случае каскадная схема суммирования результатов поэлементного умножения вырождается и операция умножения строки матрицы на вектор полностью выполняется на единственном процессоре. Получаемая при таком подходе вычислительная схема может быть конкретизирована следующим образом:
- на каждый из имеющихся процессоров пересылается вектор и  строк матрицы;
строк матрицы;
- выполнение операции умножения строк матрица на вектор выполняется при помощи обычного последовательного алгоритма.
Следует отметить, что размер матрицы может оказаться не кратным количеству процессоров и тогда строки матрицы не могут быть разделены поровну между процессорами. В этих ситуациях можно отступить от требования равномерности загрузки процессоров и для получения более простой вычислительной схемы принять правило, что размещение данных на процессорах осуществляется только построчно (т.е. элементы одной строки матрицы не могут быть разделены между несколькими процессорами). Неодинаковое количество строк приводит к разной вычислительной нагрузке процессоров; тем самым, завершение вычислений (общая длительность решения задачи) будет определяться временем работы наиболее загруженного процессора (при этом часть от этого общего времени отдельные процессоры могут простаивать из-за исчерпания своей доли вычислений). Неравномерность загрузки процессоров снижает эффективность использования МВС и, как результат рассмотрения данного примера можно заключить, что проблема балансировки относится к числу важнейших задач параллельного программирования.
2. Оценка показателей эффективности алгоритма. Время выполнения параллельного алгоритма определяется оценкой
 ,
,
где величина  есть наибольшее количество строк, загружаемых на один процессор. С учетом данной оценки показатели эффективности предлагаемой вычислительной схемы имеют вид:
есть наибольшее количество строк, загружаемых на один процессор. С учетом данной оценки показатели эффективности предлагаемой вычислительной схемы имеют вид:
 ,
,  .
.
При кратности размера матрицы и количества процессоров показатели ускорения и эффективности алгоритма приводятся к виду:
 ,
, 
и принимают, тем самым, максимально возможные значения.
3. Выбор топологии вычислительной системы. В соответствии с характером выполняемых межпроцессорных взаимодействий в предложенной вычислительной схеме в качестве возможной топологии МВС может служить организация процессоров в виде звезды (см. рис. 1.1). Управляющий процессор подобной топологии может использоваться для загрузки вычислительных процессоров исходными данными и для приема результатов выполненных вычислений.
Дата добавления: 2015-04-11; просмотров: 38 | Поможем написать вашу работу | Нарушение авторских прав |