Читайте также:
|
Группа статистических критериев, которые включают в расчет параметры вероятностного распределения признака (средние и дисперсии).
· t-критерий Стьюдента
· Критерий Фишера
· Критерий отношения правдоподобия
1.4. Типы переменных и типы шкал, ограничения, накладываемые типом переменной на применимость к их исследованию статистических критериев, методов и процедур.
Типы кодирования переменных - в статистическом пакете SPSS предусмотрено 8 типов кодирования переменных. Основные - строчные (STRING) и числовые (NUMERIC) переменные, существуют также дата (DATE), денежные (DOLLAR) и т.д. Строчные переменные используются достаточно редко (ответы на открытые вопросы).
| Тип шкалы | Предпосылки | Допустимые операции | Примеры |
| 1.1 Номинальная | Существуют определенные равенства/неравенства Xa=Xb, Xa≠Xb | Вычисление частот, частностей, моды, коэфициентов сопряженности | Имена, Метки, Номера игроков |
| 1.2 Порядковая | Определимость отношений порядка (больше-меньше) | Суммирование частот, вычисление медианы и ранговых коэфициентов корреляции | Рейтинг, Оценки, Баллы. |
| 2.1 Интервальная | Установление равенства интервалов, относительный ноль. | Расчет средних, дисперсии, коэфицинтов корреляции | Даты, Температура |
| 2.2Абсолютная (отношений) | Установлено равенство отношений. Абсолютный ноль. | Все операции с числами | Длина, Вес |
2.1. Исследование связи номинальных признаков. Понятие статистической связи между номинальными признаками.
В статистическом анализе существуют различные методы, позволяющие изучать взаимосвязи номинальных признаков. Наиболее популярным из них является метод построения таблиц сопряженности (кросс-табуляция).
Формально говоря, связь номинальных признаков понимается как более частая (или наоборот, более редкая) совместная встречаемость отдельных комбинаций категорий по сравнению с ожидаемой встречаемостью – ситуацией чисто случайного распределения объектов по категориям двух признаков.
2.2. Основные статистики таблиц сопряженности: статистики клеток, статистики, рассчитываемые для таблицы в целом. Критерии и коэффициенты связи между номинальными признаками (определение наличия и силы связи между признаками, измеренными номинальной шкалой).
| Номинальные | ранговые | интервальные | |
| Номинальные | X², V-Крамер | X², V-Крамер | |
| Ранговые | X², V-Крамер | X², V-Крамер, Спирмен, Б-тау, С-тау (Кенделл, Стюарт) | |
| интервальные | Параметрич/непараметрич методы (Фишер, Стьюдент, Манна-Уитни, K-W) | Пирсон |
Только в квадратике линейные типы связей. Если ранговые признаки корреляции = 0, то другая связь/НЕ линейная. Где нет номинальных переменных – там нелинейные формы связи.
Таблицей сопряженности называется прямоугольная таблица, по строкам которой указываются категории одного признака, а по столбцам – категории другого. Каждый объект совокупности попадает в какую-либо из клеток этой таблицы в соответствии с тем, к какой категории он относится по каждому из двух признаков. Таким образом, в клетках таблицы стоят числа, представляющие собой частоты совместной встречаемости категорий двух признаков (например, число людей, принадлежащих конкретной социальной группе и при этом входящих в определенную партию). В зависимости от характера распределения этих частот внутри таблицы можно судить о том, существует ли связь между признаками.
Таблицы сопряженности для пары переменных X и Y содержат частоты Nij, с которыми встретилось сочетание i-го значения X и j-го значения Y. Кроме того, в таблице обязательно присутствуют маргинальные частоты Ni.- равные сумме чисел Nij по строке; N.j - сумме по столбцу (частоты i-го значения X и j-го значения Y, подсчитанные независимо) и N - общее число объектов. Таблица, заполненная одними частотами Nij, обычно не имеет смысла, так как не проясняет должным образом взаимосвязи между переменными. Для исследования взаимосвязи необходимы статистики взаимосвязи переменных и статистики связи значений.
статистика Zij=(Nij-Eij)/σij - стандартизованное смещение частоты; Иными словами, Zij представляет собой отклонение наблюдаемой частоты от ожидаемой, измеренное в числе стандартных отклонений. При этом стандартное отклонение вычисляется исходя из предположения, что Nij это случайная величина, имеющая гипергеометрическое распределение:

Если переменные независимы, то, при больших N, случайная величина Zij имеет нормальное распределение с параметрами (0,1). Для нее практически невероятно отклонение, большее трех стандартных отклонений, т.к. вероятность такого значения составляет менее 0.0027 (правило "трех сигм"). Поэтому, если мы получаем значение Zij, превышающее 3, то можем считать, что i-ое значение и j-ое значения X и Y связаны.
Для характеристики связи номинальных переменных наиболее часто используется критерий Xи-квадрат (CHISQ), основанный на вычислении статистики
CHISQ=  .
.
Эта статистка показывает расстояние эмпирически полученной таблицы сопряженности от ожидаемой теоретически: расстояние между значениями выборочной таблицы Nij и ожидаемой в условиях независимости таблицы Eij. Само по себе значение статистики ни о чем не говорит, важно знать вероятность получения расстояния CHISQ, большего, чем наблюдаемое на случайной выборке. Эта вероятность называется наблюдаемой значимостью и обозначается словом SIGNIFICANCE (возможны сокращения - Sig., P -значения). значение Sig < 0,05 àвзаимосвязь переменных, т. к. значение статистики попадает в критическую область и гипотезу о независимости переменных следует отвергнуть. Рекомендуется использовать критерий хи-квадрат в CROSSTABS для переменных с небольшим числом значений, что достигается перекодировкой переменных.
логарифм отношения правдоподобия LI. Более устойчивое к объему выборки.
Измерение СИЛЫ связи между номинальными переменными: 1. Коэффициент Пирсона PHI =  ,
,  , где r – число строк, с – число столбцов. 2. Более устойчив к размерности выборки коэффициент контингенции:
, где r – число строк, с – число столбцов. 2. Более устойчив к размерности выборки коэффициент контингенции:  , 0
, 0  CC <1; 3. коэффициент Крамера
CC <1; 3. коэффициент Крамера  , где к =min [ r, c ],
, где к =min [ r, c ],  .
.
3.1.Исследование связи признаков, измеренных ранговыми и интервальными шкалами. Критерии и коэффициенты оценки связи признаков, измеренных ранговой шкалой (тау-b, тау-с, коэффициент корреляции Спирмена). Понятия связи признаков и корреляции между признаками. Наличие, сила, направленность связи признаков. Коэффициент корреляции Пирсона, коэффициент частной корреляции: ограничения, связанные с типом и распределением исследуемых признаков. Способы исследования нелинейных форм связи между признаками, измеренными ранговой и интервальной шкалой.
Ранговые переменные – в них можно установить порядок между значениями (Пр. «хорошо», «средне», «плохо»). Также количественные переменные, такие как возраст, доход, также можно использовать в качестве ранговых. Ранговые критерии — это статистические тесты, в которых вместо выборочных значений используются их ранги (номера элементов в упорядоченной по возрастанию выборке). Большинство ранговых критериев являются непараметрическими, хотя среди ранговых критериев встречаются и параметрические.
Критерии корреляции. Задана выборка пар наблюдений  объёма
объёма  . Проверяется гипотеза о наличии корреляции между случайными величинами
. Проверяется гипотеза о наличии корреляции между случайными величинами  и
и  . Для пары объектов (i, j) рассматривается, одинаково ли упорядочиваются объекты и по переменной X и по Y. Если Xi < Xj и Yi < Yj или Xi > Xj и Yi > Yj, то упорядочения одинаковы, если Xi < Xj и Yi > Yj или Xi > Xj и Yi < Yj – упорядочения не одинаковы. Число одинаковых упорядочений для всех пар объектов по X, Y обозначим Р; число разных – Q.
. Для пары объектов (i, j) рассматривается, одинаково ли упорядочиваются объекты и по переменной X и по Y. Если Xi < Xj и Yi < Yj или Xi > Xj и Yi > Yj, то упорядочения одинаковы, если Xi < Xj и Yi > Yj или Xi > Xj и Yi < Yj – упорядочения не одинаковы. Число одинаковых упорядочений для всех пар объектов по X, Y обозначим Р; число разных – Q.
Коэффициент корреляции Кенделла — мера линейной связи между случайными величинами. Кендалл - величина BTAU =(P – Q) / T, где T – нормирующий знаменатель, такой, чтобы величина BTAU изменялась от –1 до 1. BTAU = –1 означает, что получена полная отрицательная связь X и Y, BTAU =1 – полная положительная связь. Коэффициент Стюарта CTAU несколько отличается нормирующим знаменателем. С точки зрения использования отличие их в том, что BTAU предпочтительнее использовать для квадратных таблиц сопряженности, то есть когда r = c. Например, с помощью этих коэффициентов можно проверить гипотезу независимости переменных «степень противостояния СССР и Японии» и «степень альтруизма» против гипотезы их зависимости: одинаковой или противоположной упорядоченности.
Коэффициент ранговой корреляции Спирмена. Степень зависимости двух случайных величин (признаков) X и Y. Нулевая гипотеза  : Выборки и не коррелируют (
: Выборки и не коррелируют ( ). Практический расчет: 1) Сопоставить каждому из признаков их порядковый номер (ранг) по возрастанию (или убыванию). 2) Определить разности рангов каждой пары сопоставляемых значений. 3) Возвести в квадрат каждую разность и суммировать полученные результаты. 4) Вычислить коэффициент корреляции рангов по формуле:.
). Практический расчет: 1) Сопоставить каждому из признаков их порядковый номер (ранг) по возрастанию (или убыванию). 2) Определить разности рангов каждой пары сопоставляемых значений. 3) Возвести в квадрат каждую разность и суммировать полученные результаты. 4) Вычислить коэффициент корреляции рангов по формуле:.  , где
, где  - сумма квадратов разностей рангов, а
- сумма квадратов разностей рангов, а  - число парных наблюдений. Значение коэффициента меняется от −1 (последовательности рангов полностью противоположны) до +1 (последовательности рангов полностью совпадают). Нулевое значение показывает, что признаки независимы.
- число парных наблюдений. Значение коэффициента меняется от −1 (последовательности рангов полностью противоположны) до +1 (последовательности рангов полностью совпадают). Нулевое значение показывает, что признаки независимы.
Критерии сдвига: Проверяется гипотеза сдвига, согласно которой распределения двух выборок имеют одинаковую форму и отличаются только сдвигом на константу. Задача: различия двух групп по исследуемой переменной. Пусть заданы две выборки  , взятые из неизвестных непрерывных распределений
, взятые из неизвестных непрерывных распределений  и
и  соответственно. Нулевая гипотеза —.
соответственно. Нулевая гипотеза —.  . Наиболее частая альтернативная гипотеза -
. Наиболее частая альтернативная гипотеза - 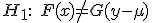 . U-критерий Манна-Уитни — непараметрический статистический критерий, используемый для оценки различий между двумя выборками по признаку, измеренному в количественной или порядковой шкале. Основан на сравнении средних рангов в выделенных группах. Критерий – сумма рангов объектов в меньшей группе. Логика построения: 1. Ранжирование объектов по исследуемому признаку 2. Сортировка объектов по двум группам 3. расчет суммы рангов по каждой из групп 4. расчет среднего ранга для каждой из групп. Н0: средние ранги в группах статистически значимо не отличаются. Если гипотеза о совпадении распределений подтверждена, значит, средние ранги в группах близки. Смотрим на эмпирический уровень значимости.
. U-критерий Манна-Уитни — непараметрический статистический критерий, используемый для оценки различий между двумя выборками по признаку, измеренному в количественной или порядковой шкале. Основан на сравнении средних рангов в выделенных группах. Критерий – сумма рангов объектов в меньшей группе. Логика построения: 1. Ранжирование объектов по исследуемому признаку 2. Сортировка объектов по двум группам 3. расчет суммы рангов по каждой из групп 4. расчет среднего ранга для каждой из групп. Н0: средние ранги в группах статистически значимо не отличаются. Если гипотеза о совпадении распределений подтверждена, значит, средние ранги в группах близки. Смотрим на эмпирический уровень значимости.
«Хи-квадрат». Непараметрический, одновыборочный тест. Тип переменной: номинальные, ранговые. Служит для проверки взаимосвязи между номинальными переменными и коэффициентами ранговой корреляции. Для проверки репрезентативности выборки (сравнение со структурой генеральной совокупности). Eij – доли, ожидаемые частоты. Структура распределения признака в генеральной совокупности (доля людей, соответствующих значениям признака в ГС). Nij – структура признака в выборочной совокупности. Н0: Ni=Ei – выборка репрезентативна по исследуемому признаку. Процедура: необходимо задать структуру ГС (все категории равны). Формула по аналогии с параметрической:  Позволяет определить – нужен ли ремонт выборки в данной ситуации. Непараметрический аналог одновыборочного Т-теста (соответствие долей мужчин и женщин в выборке их представленности в ГС). Необходимо чтобы количество объектов было больше 5. Смотрим на эмпирический уровень значимости. Если меньше 0.05 принимаем альтернативную гипотезу о наличии статистически значимых различий в распределениях между выборочной и генеральной совокупностями.
Позволяет определить – нужен ли ремонт выборки в данной ситуации. Непараметрический аналог одновыборочного Т-теста (соответствие долей мужчин и женщин в выборке их представленности в ГС). Необходимо чтобы количество объектов было больше 5. Смотрим на эмпирический уровень значимости. Если меньше 0.05 принимаем альтернативную гипотезу о наличии статистически значимых различий в распределениях между выборочной и генеральной совокупностями.
ДВУХВЫБОРОЧНЫЕ ТЕСТЫ СВЯЗАННЫХ ВЫБОРОК: Связанные – один объект может попадать как в одну, так и в другую группу. Используются ранговые и интервальные переменные.
1. Двухвыборочный критерий знаков (направленность различий). Выдают таблицу с отрицательной разницей (знак меньше), положительной (знак больше), связанные ранги (знак равенства). Статистика критерия - стандартизованная частота положительных разностей. Смотрим на эмпирический уровень значимости, принимаем гипотезу о наличии / отсутствии различий; смотрим на z-статистику и делаем вывод о знаке (направленности различий). Пр. худели ли м в 1994 году или наоборот.
2. Двухвыборочный знаково-ранговый критерий Вилксона (направленность различий + выраженность - сила). Статистика критерия – стандартизованная разность сумм. Проверка – не произошло ли между измерениями событие, существенно изменившее иерархию объектов? Он позволяет установить не только направленность изменений, но и их выраженность, то есть способен определить, является ли сдвиг показателей в одном направлении более интенсивным, чем в другом. Сопоставляются абсолютные величины выраженности сдвигов в том или ином направлении. Для этого сначала все абсолютные величины сдвигов ранжируются, а потом суммируются ранги. Если сдвиги в ту или иную сторону происходят случайно, то и суммы их рангов окажутся примерно равны. Если же интенсивность сдвигов в одну сторону больше, то сумма рангов абсолютных значений сдвигов в противоположную сторону будет значительно ниже, чем это могло бы быть при случайных изменениях.
Расчет суммы рангов и средний ранг. Для k несвязанных выборок:
1. Тест медиан (ранговые) – грубый и простой, лучше использовать в паре со вторым тестом. Основан на критерии Хи-квадрат, сравнивает k групп по исследуемому признаку. Механизм: 1. рассчитывается медиана в целом по совокупности. 2. В каждой из групп выделяется доля людей, имеющих значения больше медианы и вторая – равные или меньше медианы. 3. Строится таблица сопряженности: 1 признак – Группообразующий, 2 – принимает значения больше медианы или меньше и равно. Далее применяется критерий Хи-квадрат. Если величина наблюдаемой значимости критерия мала, то распределение исследуемой переменной в группах различается существенно.
2. Одномерный дисперсионный анализ Краскела-Уоллиса. (интервальные, ранговые). Задача: сравнение нескольких групп по исследуемому признаку. Продолжение теста Манна-Уитни, логика расчета та же. Логика построения: 1. Ранжирование объектов по исследуемому признаку 2. Сортировка объектов по группам 3. расчет суммы рангов по каждой из групп 4. расчет среднего ранга для каждой из групп. Н0: средние ранги в группах статистически значимо не отличаются. Н1: хотя бы один средний ранг отличается. Выдается число степеней свободы. Критерий Хи-квадрат.
Дата добавления: 2015-04-11; просмотров: 49 | Поможем написать вашу работу | Нарушение авторских прав |