|
Читайте также: |
 в з = å k i x i ¤ å ki, где k – коэффициент взвешивания, в качестве которого используют отдельные значения какого либо параметра, на который «взвешивается» содержание (например, мощность рудного тела, площадь, объем, интервал опробования и до.).
в з = å k i x i ¤ å ki, где k – коэффициент взвешивания, в качестве которого используют отдельные значения какого либо параметра, на который «взвешивается» содержание (например, мощность рудного тела, площадь, объем, интервал опробования и до.).
При статистической проверке гипотез о сходстве или различии двух объектов используют критерии согласия, которые вычисляют по определенным формулам, используя параметры распределения случайной величины в двух исследуемых выборках. Вычисленные по эмпирическим данным значения критериев согласия сравнивают с табличными значениями, которые зависят от количества точек наблюдения и уровня значимости. Критерий Фишера(F) позволяет сравнивать выборки по их дисперсиям.

С помощью критерия Стьюдента(t) сравниваются средние значения.

Если эти критерии меньше табличных значений, можно принимать гипотезу о равенстве средних и дисперсий двух сравниваемых объектов.
При проверке гипотезы о статистической однородности объекта выборка разделяется на неоднородные совокупности, и выделяются аномальные (редко встречающиеся) значения. Это делается с помощью графических процедур (гистограмм, «ящика с усами» и др.), а также используя классификационные анализы и различные критерии. Так, при нормальном распределении для выделения аномальных значений используется критерий Смирнова (t):
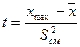 ,
,
где  - значение максимального члена выборки,
- значение максимального члена выборки,  - смещенная дисперсия:
- смещенная дисперсия:

Если вычисленный критерий t больше табличного значения, то максимальное значение выборки следует считать аномальным. Табличное значение находится по справочникам в таблицах распределения Смирнова.
Другой пример неоднородности выборки – когда количество наблюдений, принадлежащих к разным геологическим совокупностям велико. Это наглядно видно на гистограмме по нескольким модальным значениям случайной величины.
Двумерные статистические модели описывают системы, путем совместного рассмотрения двух признаков и их взаимосвязи с целью выяснения общей структуры изучаемого объекта. Для этого в геологической практике наиболее часто используют парный корреляционный и двумерный регрессионный анализы.
Корреляционный анализ позволяет по выборочным данным оценить наличие или отсутствие связи между изучаемыми признаками, характер этой связи (прямая или обратная), а также её силу с помощью коэффициента корреляции. Существуют различные процедуры корреляционного анализа – линейная корреляция, ранговая, частная и др. Парная линейная корреляция используется при одинаковой размерности исследуемых признаков и нормальном законе распределения. Коэффициент парной линейной корреляции (r) при этом рассчитывается по формуле:
 ,
,
где  и
и  - выборочные оценки средних значений случайных величин X и Y, Sx и Sy – выборочные оценки их стандартных отклонений, n – количество сравниваемых пар значений.
- выборочные оценки средних значений случайных величин X и Y, Sx и Sy – выборочные оценки их стандартных отклонений, n – количество сравниваемых пар значений.
При небольшом количестве точек наблюдения (или если распределения существенно отличаются от нормального закона), а также при различной размерности изучаемых признаков используют ранговый коэффициент корреляции:
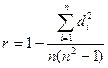 ,
,
где di – разность рангов сопряженных значенийизучаемых величин xi и yi; n – количество пар в выборке;
½ r ½£ 1.
Полученные значения коэффициентов корреляции сравниваются с критическими значениями (rкр.) , которые зависят от количества точек наблюдения и заданного уровня значимости. Критические значения можно вычислить по специальным формулам или взять из справочников по математической статистики. Если ½ r ½> rкр., то принимается гипотеза о наличии корреляционной связи между двумя изучаемыми признаками, т. е. связь между признаками – значимая. При этом отрицательное значение r свидетельствует об обратной связи, а положительное – о прямой.
Регрессионный анализ ориентирован на исследование количественной зависимости одной случайной величины Y от набора значений другой { Xi }= (x1, x2,… xn). Его основными задачами являются: 1) установление формы зависимости Y от Xi; 2) определение вида уравнения регрессии; 3) прогнозирование значений результирующей переменной Y (которую получить трудоёмко) по известным значениям x1, x2,… xn (которые определяются более доступными экспресс-методами). При линейной зависимости значений двух изучаемых признаков уравнение регрессии имеет вид:
 ,
,
где а и b – коэффициенты, зависящие соответственно от положения начальных точек линий регрессии и угла наклона прямой регрессии к оси абсцис; если а = 0, линия регрессии проходит через начало координат.
С помощью уравнения регрессии вначале оценивают зависимость между необходимыми признаками в эталонной выборке. Затем эту закономерность переносят на малоизученный объект, который аналогичен эталонному, но по которому имеются данные только по признаку X. Подставляя в уравнение регрессии значения x1, x2,… xn , можно в каждой точке наблюдения рассчитать значения y1, y2,… yn .
Многомерные статистические модели позволяют описать геологические объекты как системы множества взаимосвязанных признаков. Эти модели в геологии обычно изучают с помощью процедур многомерного корреляционного анализа, многомерного регрессионного анализа, кластерного, факторного, дискриминантного анализов.
Уравнение множественной регрессии при линейной зависимости между признаками имеет вид:
Y = b1X1+b2X2+…bpXp+e,
где Y – зависимая переменная, X1, X2, Xp – независимые переменные, b - коэффициенты регрессии, e - свободный член уравнения (n- многомерный вектор случайных отклонений). Процедура данного анализа заключается в вычислении значений b и e. Уравнение множественной регрессии позволяет оценить совместное влияние всех изучаемых параметров на зависимую переменную.
Кластерный анализ – совокупность методов классификации и разбивка объектов и многомерных наблюдений на однородные группы. Составление классификаций подчиняется следующим правилам:
- в одной классификации применяется одно и то же основание;
- объем классифицируемого класса равняется сумме объемов подклассов;
- классы и подклассы не пересекаются.
Процедура кластерного анализа предусматривает возможность классификации точек наблюдений в исследуемой выборке, а также самих признаков. В качестве меры сходства при классификациях применяют различные дистанционные коэффициенты: m -мерноеэвклидово расстояние, коэффициенты корреляции и др. Задачи классификации разделяются по типу априорной информации на три типа: 1) число классов задано априорно; 2) число классов неизвестно и его следует определить; 3) число классов неизвестно, но его определение не входит в условие задачи. Две последние ситуации приводят к построению иерархических деревьев – дендрограмм. Это графики, на которых по одной оси располагаются символические обозначения объектов исследования, а по другой оси – минимальные значения дистанционных коэффициентов, соответствующих каждому шагу классифицирующей процедуры. Таким образом, ось с дистанционными коэффициентами используется для масштабного представления иерархических уровней группирования.
Дискриминантный анализ является статистическим средством разделения (дискриминации) многомерных нормально распределенных совокупностей на группы таким образом, чтобы была достигнута максимальная однородность внутри групп и минимальная между ними. В основе разделения на группы лежит нахождение дискриминантной функции по эталонным выборкам и расчет порогового значения. При построении дискриминантной функции используется небольшое количество (5-7) информативных признаков которые имеют существенные различия значений в двух эталонных объектах. Далее, используя полученную дискриминантную функцию и пороговое значение, производится процедура отнесения любой исследуемой точки наблюдения к какому-либо из двух разных эталонных объектов (например, рудовмещающим или безрудным метасоматитам).
Факторный анализ приспособлен для исследования сложных природных систем, формирующихся под воздействием и влиянием разнообразных факторов. Предпосылкой метода служит представление о том, что корреляция между признаками, характеризующими природную систему, является следствием их линейной зависимости от определенного числа неизвестных «простых» характеристик, не коррелированных между собой. Эти простые характеристики можно считать «причинами», а наблюдаемые характеристики (показатели) – «следствиями». Суть анализа сводится к поиску этих независимых (ортогональных) показателей, которые носят название главных компонент или факторов.
Результаты факторного анализа приводятся в виде таблицы - матрицы факторных нагрузок. Факторные нагрузки отражают силу влияния фактора на изменения каждого признака; по нему определяется принадлежность этого признака к соответствующей совокупности. По максимальным (значимым) факторным нагрузкам выделяют группу взаимосвязанных признаков. Для каждого фактора рассчитывается также его вес в % или долях единицы. Порядок выделения факторов соответствует убыванию их веса. Первый фактор всегда основной, он ответственен за формирование наиболее тесных связей между самой многочисленной совокупностью показателей. Достоинством факторного анализа является возможность выявления связи одного и того признака одновременно с двумя факторами.
Конкретное использование факторного анализа требует построение модели интерпретации его результатов. Эта интерпретация должна отвечать цели исследования.
С помощью факторного анализа можно группировать точки наблюдения в пространстве двух главных факторов. Процедура факторного анализа позволяет не только выявлять совокупности признаков по их взаимосвязям с факторами, но и рассчитывать значения каждого фактора в конкретной точке наблюдения. Эти значения можно картировать для выявления зональности, аномалий, возникающих под влиянием определенных факторов, которые можно интерпретировать как геологические причины (например, седиментогенез, гидротермальный процесс, метаморфизм и т.п.).
Моделирование пространственных переменных позволяет выявить пространственные закономерности различных геологических, геофизических, геохимических и др. признаков в исследуемых объемах недр.
Одним из методов пространственного моделирования является тренд-анализ. С помощью этого анализа обычно производят сглаживание исходных данных скользящими статистическими окнами, а также выявление фона, аномалий, тренда (закономерного изменения значений признака).
Математические методы с использованием компьютерных технологий широко применяются для моделирования геологических процессов, прогнозирования и оценки геологических ресурсов и подсчета запасов полезных ископаемых, поисков оптимальных решений в процессе проектирования геологоразведочных работ, а также для решения других прикладных и научных задач в различных областях геологии.
Дата добавления: 2015-04-20; просмотров: 22 | Поможем написать вашу работу | Нарушение авторских прав |