Определение. Пусть I = { i 1, i 2, i 3, … i n} – множество (набор) элементов. Пусть D – множество транзакций, где каждая транзакция T – это набор элементов из I, T  I. Каждая транзакция представляет собой бинарный вектор, где t [ k ]=1, если i k элемент присутствует в транзакции, иначе t [ k ]=0. Мы говорим, что транзакция T содержит X - некоторый набор элементов из I, если X T. Ассоциативным правилом называется импликация X
I. Каждая транзакция представляет собой бинарный вектор, где t [ k ]=1, если i k элемент присутствует в транзакции, иначе t [ k ]=0. Мы говорим, что транзакция T содержит X - некоторый набор элементов из I, если X T. Ассоциативным правилом называется импликация X  Y, где X
Y, где X 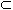 I, Y I и X
I, Y I и X  Y =
Y =  . Правило X Y имеет поддержку s (support), если s % транзакций из D содержат X
. Правило X Y имеет поддержку s (support), если s % транзакций из D содержат X  Y, supp (X Y) = supp (X Y). Достоверность правила показывает какова вероятность того, что из X следует Y. Правило X Y справедливо с достоверностью c (confidence), если c % транзакций из D, содержащих X, также содержат Y, conf (X Y) = supp (X Y)/ supp (X).
Y, supp (X Y) = supp (X Y). Достоверность правила показывает какова вероятность того, что из X следует Y. Правило X Y справедливо с достоверностью c (confidence), если c % транзакций из D, содержащих X, также содержат Y, conf (X Y) = supp (X Y)/ supp (X).
Проанализируем это на конкретном примере: "75% транзакций, содержащих хромосому типа 1, также содержат хромосому типа 2. 3% от общего числа всех транзакций в базе содержат оба типа хромосом". 75% – это достоверность (confidence) правила, 3% это поддержка (support), иными словами "Хромосома типа 1" "Хромосома типа 2" с вероятностью 75%.
Другими словами, целью анализа является установление следующих зависимостей: если в транзакции встретился некоторый набор элементов X, то на основании этого можно сделать вывод о том, что другой набор элементов Y также же должен появиться в этой транзакции. Установление таких зависимостей дает нам возможность находить очень простые и интуитивно понятные правила.
Алгоритмы поиска ассоциативных правил предназначены для нахождения всех правил X Y, причем поддержка и достоверность этих правил должны быть выше некоторых наперед определенных порогов [21, 31], называемых соответственно минимальной поддержкой (minsupport) и минимальной достоверностью (minconfidence).
Задача нахождения ассоциативных правил разбивается на две подзадачи:
1. Нахождение всех наборов элементов, которые удовлетворяют порогу minsupport. Такие наборы элементов называются часто встречающимися.
2. Генерация правил из полученных в п. 1 наборов элементов с достоверностью, удовлетворяющей порогу minconfidence.
Значения параметров «минимальная поддержка» и «минимальная достоверность» выбираются таким образом, чтобы ограничить количество найденных правил. Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитикам или настолько очевидные, что нет никакого смысла проводить такой анализ. С другой стороны, низкое значение поддержки ведет к генерации огромного количества правил, что, конечно, требует существенных вычислительных ресурсов. Тем не менее, большинство интересных правил находится именно при низком значении порога поддержки. Хотя слишком низкое значение поддержки ведет к генерации статистически необоснованных правил.
Поиск ассоциативных правил совсем не тривиальная задача, как может показаться на первый взгляд. Одна из проблем – алгоритмическая сложность при нахождении часто встречающих наборов элементов, т.к. с ростом числа элементов в I (| I |) экспоненциально растет число потенциальных наборов элементов.
Список литературы
(жирным шрифтом выделена рекомендованная литература)
1. Brand E., Gerritsen R. Naive-Bayes and Nearest Neighbor // DBMS Magazine. – 1998. – №7.
2. Brin S. et al. Dynamic Itemset Counting and Implication Rules for Market Basket Data. // Proc. ACM SIGMOD Int. l Conf. Management of Data, ACM Press, 1997.
3. Cannon D., Wheeldon D. Service Operation. The Stationary Office, 2007.
4. ИТ Сервис менеджмент. Введение (пер. с англ.). Изд-во Van Haren Publishing, 2003. – 225 с.
5. Fayyad, Piatetsky-Shapiro, Smyth, Uthurusamy. Advances in Knowledge Discovery and Data Mining. – AAAI/MIT Press, 1996;
6. Iqbal M., Nieves M. Service Strategy. – The Stationary Office, 2007.
7. Lloyd V., Rudd C. Service Design. – The Stationary Office, 2007.
8. Lacy S., Macfarlane I. Service Transition. – The Stationary Office, 2007.
9. Parsaye K. A Characterization of Data Mining Technologies and Processes Database. // Programming and Design. – 1996. – № 4.
10. Paul S., MacLennan J., Tang Z., Oveson S. Data Mining Tutorial. – Microsoft Press, 2005.
11. Piatetsky-Shapiro. Machine, Learning and Data Mining. – Course Notes, 2004.
12. Srikant R., Agrawal R. Mining quantitative association rules in large relational tables //In Proceedings of the ACM SIGMOD Conference on Management of Data. Montreal, Canada, June 1996.
13. Андреев И. Деревья решений – CART математический аппарат. / "Exponenta Pro. Математика в приложениях". - 2004, - №3.
14. Буров К., Обнаружение знаний в хранилищах данных. / Открытые системы. – 1999. – №5.
15. Гончаров М. Модифицированный древовидный алгоритм Байеса для решения задач классификации. – Business Data Analytics, 2007.
16. Дюк В., Асеев М.. Поиск if-then правил в данных: проблемы и перспективы, Тр. СПИИРАН // РАН, С.-Петерб. ин-т информатики и автоматизации, 2005.
17. Дюк В. Методология поиска логических закономерностей в предметной области с нечеткой системологией. – Дис. д-ра техн. наук, 2005.
18. Дюк В. Осколки знаний // Экспресс-Электроника. – 2002. – № 6.
19. Дюк В., Самойленко А., Data Mining. Учебный курс. – СПб.: Питер, 2001. – 368 с.
20. Елманова Н. Введение в DataMining. // КомпьютерПресс. – 2003. – №8.
21. Ларин С. Выявление обобщенных ассоциативных правил – описание алгоритма // Exponenta Pro. Математика в приложениях. – 2003. – №3.
22. Ларин С. Использование деревьев решений для оценки кредитоспособности физических лиц // Банковское дело. – 2004. – №3.
23. Ларин С. Применение ассоциативных правил для стимулирования продаж // Exponenta Pro. Математика в приложениях. – 2005. – №6.
24. Леонов В. Краткий обзор методов кластерного анализа // Компьютерра. – 2004. – №9.
25. Паклин Н. Логистическая регрессия и ROC-анализ – математический аппарат. – BaseGroup Labs, 2006.
26. Официальный сайт Intersoft Lab (www.intersoft.ru).
27. Официальный сайт SPSS в РФ (http://www.spss.ru).
28. Струнков Т. Что такое генетические алгоритмы // PC Week RE. – 1999. – №19.
29. Чубукова И. Data Mining. – Бином, 2006. – 384 c.
30. Шахиди А. Введение в анализ ассоциативных правил. – BaseGroup Labs, 2004.
31. Шахиди А. Выявление обобщенных ассоциативных правил – описание алгоритма // Exponenta Pro. Математика в приложениях. – 2003. – №3.
32. Шахиди А. Деревья решений – C4.5 математический аппарат. – BaseGroup Labs, 2007.
33. Шахиди А., Деревья решений – основные принципы работы. – BaseGroup Labs, 2006.
34. Электронный учебник по статистике StatSoft. – М.: StatSoft, 2003, (http://www.statsoft.ru/home/textbook/default.htm.).
35. Безруких М.М., Фарбер Д.А. Психофизиология. Словарь. Психологический лексикон. Энциклопедический словарь в шести томах / Ред.-сост. Л.А. Карпенко. Под общ. ред. А.В. Петровского. – М.: ПЕР СЭ, 2006.
Дата добавления: 2015-09-12; просмотров: 29 | Поможем написать вашу работу | Нарушение авторских прав |