|
Читайте также: |
A <--> B
Это означает, что каждому значению (экземпляру) элемента А соответствует одно и только одно значение (экземпляр) элемента В.
Например, табельный номер TN - Фамилия FIO:
TN <--> FIO.
2) одно-многозначное соответствие (1:М):
A<->>B
Каждому значению поля А соответствует несколько значений поля В.
Например, Номер группы <->> ФИО студента.
Множество значений поля В, соответствующих значению поля А, может быть пустым (нет ни одного значения соответствующего значению поля А) или представлено одним, двумя или n значениями.
3) много-однозначное соответствие (М:1):
А<<->B
Например, ФИО студента <<-> Номер группы.
4) много-многозначное соответствие (М:М):
A<<->>B
Например, Изделие <<->> Покупатель.
 Изделия Изделия
| Покупатели | |
| Изделие 1 | Покупатель 1 | |
| Изделие 2 | Покупатель 2 | |
| Изделие 3 | Покупатель 3 | |
| Изделие 4 | Покупатель 4 | |
| Изделие 5 | Покупатель 5 | |
| Изделие 6 | Покупатель 6 | |
| Изделие 7 | Покупатель... | |
| Изделие 8 | Покупатель m | |
| Изделие... | ||
| Изделие n |
Перечислить элементы логического проектирования при разработке информационного обеспечения.
Логическое проектирование включает два этапа:
Первый этап.
1) составление списка всех полей (данных) для описания предметной области и их характеристик, в том числе, наименований, имен, типов, размеров полей;
2) установление логических связей между полями;
3) составление графа связей, образование групп полей, формирование записи, выделение ключей;
4) составление графического и словесного описания логической структуры данных;
5) описание логики взаимосвязи полей и содержания полей;
6) документирование в соответствии с принятыми соглашениями или ГОСТ.
В итоге получаем логическое представление данных.
Завершив первый этап логического проектирования, т.е. создав логическое описание, проводят уточнение структуры данных в зависимости от характера использования информации. На этом этапе логического структурирования выявляют (второй этап, этап уточнения):
1) периодичность и виды обработки информации и ее отдельных частей;
2) виды запросов к информации и возможность их разрешения,
3) вопросы безопасности, целостности, защиты, модифицируемости и другие возможные про-блемы обработки информации.
Далее, проводится редактирование логической схемы, ее реструктирование, усовершенствование.
В развитых СУБД имеются средства автоматизированного логического проектирования, ведения сло-варей данных, моделирования запросов и обработки данных. В качестве инструмента проектирования структур данных могут использоваться также системы CASE (Computer Aided System Engineering) - авто-матизированные системы структурного проектирования баз данных и ИС.
Перечислить характеристики совокупностей данных.
Базы данных (файлы, наборы данных) как некоторые совокупности данных обладают определенными характеристиками. Ряд характеристик аналогичен рассмотренным ранее, а ряд присущ базам данных как специфичной совокупности данных. Перечислим основные характеристики:
1) Наименование базы (файла),
2) Идентификатор (имя),
3) Структура (схема базы, логическая, физическая структура),
4) Класс объектов,
5) Размер (объем) базы (файла),
6) Целевой характер использования информации:
а) НСИ, классификаторы,
б) оперативная, постоянная,
в) входная, выходная,
г) первичная, промежуточная, результирующая,
7) Активность данных,
8) Выборочность,
9) Изменчивость,
10) Избыточность (дублирование),
11) Атрибуты (в том числе, атрибуты доступа),
12) и другие характеристики.
Дать определение и привести примеры: Размер (объем) базы данных (файла).
Объем (размер) базы - это сумма длин всех полей всех записей базы данных.
 (не уверена)
(не уверена)
где  - длина поля j,
- длина поля j,
 - количество полей типа j в записи i,
- количество полей типа j в записи i,
m - количество полей в записи,
n - количество записей.
Дать определение и привести примеры: активность данных.
Активность данных - это характеристика, определяемая отношением числа обращений к структурному элементу данных к общему числу обращений к информации (базе данных, файлу) в некоторый интервал времени или единицу работы.

где R j - активность поля j,
kj - количество обращений к полю j,
ki - количество обращений к полю i,
1 =< i <= n, n - число полей записи.
Дать определение и привести примеры: избыточность данных.
Избыточность (дублирование) - это характеристика, определяемая отношением количества дублированных (повторившихся) данных (Vd) ко всему объему данных (V).
Kd = Vd/V
Чем ближе Kd к 0, тем лучше.
В рассмотренном выше примере данных об узлах и деталях, представленных двумя структурами данных - линейной и иерархической, хорошо иллюстрируется дублирование данных в линейной структуре (дублируются значения поля “узел” для разных деталей, входящих в один узел). В иерархической структуре дублирование полей отсутствует.
Уровни обработки информации. Основные процедуры обработки массивов информации.
Обработка информации - это преобразование некоторого исходного множества данных в другое множество.
В процессах обработки информации можно выделить несколько уровней операций обработки данных, в том числе:
-операции над элементарными данными (обычно выполняются аппаратными средствами, командами, операторами и функциями языков и систем программирования);
-операции над группами (агрегатами, сегментами, записями) данных;
-операции с файлами, массивами, базами данных.
Выделяют следующие основные процедуры обработки данных:
- сортировка (упорядочение);
- выборка;
- слияние;
- поиск;
- корректировка;
- сжатие.
Процедура сортировки данных. Ключи сортировки. Виды сортировок. Оценка числа сравнений при сортировке.
Сортировка - это процесс обработки данных, с помощью которого записи в массиве (файле, наборе данных) информации располагаются в установленном порядке согласно принятому критерию. Например, такому критерию, как "по возрастанию (убыванию) значения поля Х в качестве ключа сортировки".
Упорядоченность - это порядок размещения записей относительно друг друга. Обычно упорядоченность осуществляется по наиболее важному полю, называемому ключом сортировки.
Например, телефонный справочник квартирных телефонов:
а) упорядочен по возрастанию фамилий, и.о.;
б) в тоже время относительно адреса - телефонная книга имеет достаточно случайный характер.
Ключ сортировки может быть составным, т.е. состоять из нескольких полей. Причем, каждое поле может иметь свой порядок.
Как уже было рассмотрено, тип поля может быть числовым, текстовым, логическим и т.д. Наибольшее применение имеет принцип лексикографической упорядоченности (по возрастанию алфавита, кодов символов).
Существуют программы сортировки для выполнения этой процедуры обработки данных. Такие программы могут входить в состав ОС, систем программирования, комплексов утилит (сервисных программ) и т.д.
Файл (исходный) -> сортировка -> Файл (результирующий)
Для оценки методов упорядочения одним из основных критериев является количество операций сравнения в процессе сортировки.
Теоретически доказано, что минимально возможное число сравнений для упорядочения nэлементов (записей) приближенно оценивается по формуле:
C(n) 
С - число операций сравнения;
n - количество записей в массиве;
]x[ - наименьшее целое, не меньшее х.
Сортировка - процесс расположения записей согласно принятому критерию.
Сортировки подразделяют в зависимости от алгоритма и вида используемой при сортировке памяти на:
- внутренние (пузырьковая, Шелла, вставки, квадратичной выборки) в оперативной памяти;
- внешние (балансная, каскадная, многофазная) с использования внешних носителей информации.
Методы сортировки:
Метод пузырька.
Очень простой, но не эффективный способ. Название получил по аналогии с пузырьком, всплывающим в жидкости. Сортировка проводится по алгоритму: первый ключ сравнивается со всеми последующими, пока не будет найден ключ j-й ключ, меньший первого. Тогда ключи меняются местами, т.е. делается их перестановка. Таким образом, совершается процедура со всеми последующими ключами до конца массива. Для первого ключа требуется (n-1) сравнение. Затем берется второй ключ и процедура повторяется, осуществляется (n-2) сравнения. И т.д. до (n-1)-го ключа, который сравнивается с последним, одно сравнение.
Всего проводится сравнений:
C(n)=(n-1)+(n-2)+...+1=n(n-1)/2.
Число возможных перестановок ключей: max P(n)»n(n-1)/2, среднее P(n)»n(n-1)/4.
Метод вставки.
При этом методе сортировки каждый ключ (обозначим его номером j) сравнивается с предыдущим до тех пор, пока не будет найден ключ с меньшим значением, чем ключ с номером j. Пусть это будет ключ с номером k (k<j). Тогда все ключи с номерами k+1,....j-1 сдвигаются на одну позицию вниз, а ключ j ставится на место ключа к+1. Если все впереди стоящие ключи больше ключа j, то все предыдущие сдвигаются вниз и ключ j ставится первым. Таким образом, доходят до последнего ключа n.
Оценка числа сравнений C(n)»n(n-1)/4.
Число перестановок ключей в процессе сортировки оценивается как P(n)»n(n-1)/4.
Метод Шелла.
Этот метод заключается в разбивке массива на группы и сортировке внутри этих групп. Затем группы попарно сливаются и производится сортировка внутри вновь образованных групп и т.д. На последнем этапе, когда массив представляет две отсортированные группы, он сортируется методом вставки или с помощью слияния с одновременным итоговым упорядочением.
Первоначально группы состоят из двух элементов, например, из 1-го и [n/2]+1-го, 2-го и [n/2]+2-го и т.д.
При использовании метода Шелла время сортировки пропорционально, как подтверждено экспериментально, 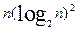 .
.
Число сравнений С(n) £ 0.5n  .
.
Внешние сортировки (на внешнем носителе):
Для больших объемов информации используются, как правило, внешние запоминающие устройства (ВЗУ) - магнитные ленты, диски. Сортировки с применением ВЗУ называются внешними. Внешние сортировки проводятся обычно в два этапа. На первом этапе выполняется внутренняя сортировка отдельных блоков информации и эти блоки записываются на внешние носители. На втором этапе эти блоки сливаются в один массив. Под слиянием будем понимать формирование из нескольких блоков такой части массива, которая упорядочена по тем же правилам, что и исходные блоки.
Существует несколько видов внешних сортировок.
Балансная сортировка.
Известны модификации этой сортировки - метод слияния, обменная сортировка.
При сортировке этим методом рабочий объем оперативной памяти делится на р-вводных и одну выводную зону. Обычно р=2. Для сортировки требуется 2р магнитных лент или файлов на магнитном диске. Исходный массив записывается на р лентах упорядоченными блоками равной длины. Другие р-лент считаются выходными. С каждой ленты считывается блок (всего р-блоков) в одну зону, информация в которой сортируется и выводится на очередную выходную ленту. Упорядоченная порция будет в р-раз больше, чем были входные порции. Это выполняется до тех пор, пока выходной порцией не окажется весь массив.
Рассмотрим пример. Пусть р=2. Массив состоит из 10 записей. Схема сортировки будет выглядеть следующим образом.
Исходный 1-й этап 2-й этап 3-й этап Выходной
массив массив
Процедура выборки информации. Критерии отбора информации.
Выборка информации - это процесс обработки массива информации (файла, набора данных), с помощью которого создается новый массив информации по заданным критериям отбора данных и со структурой данных, являющейся подмножеством данных исходного массива.
Пример.
Пусть есть список студентов некоторого факультета. Запись имеет вид:
| Фамилия, и.о. | Группа | Пол | Дата рождения | Служба в ВС |
Задача: Выбрать всех призывников и сформировать файл.
Определим условие выборки:
(пол=“М”).”И”.((16=<(Текущая дата - Дата рождения).”И”.(Текущая дата - Дата рождения)<28) *
.“И”.”НЕ”(Служба в ВС))
Структура записи результирующего файла:
| Фамилия, и.о. | Группа | Дата рождения |
 Графическое изображение выборки:
Исходный файл
Файл выборки
Документ Графическое изображение выборки:
Исходный файл
Файл выборки
Документ
|
Выборка - одна из очень распространенных операций обработки данных. Применяется как к файловым структурам, так и в базах данных.
Число выбранных записей может быть от 0 до n, где - n число записей в исходном массиве.
Критерии отбора - это логические условия, которым должны удовлетворять заданные поля исходного массива. Элементами логических условий являются поля, отношения между ними и заданными значениями полей, логические связки - и, или, нет.
Процедура поиска информации. Понятие запроса. Виды условий поиска. Эффективность поиска.
Поиск - это процедура извлечения (выделения) из некоторого множества записей такого подмножества, записи которого удовлетворяют заранее заданному условию. Условия поиска называют запросом на поиск, поисковым признаком.
Виды условий поиска:
1) по совпадению (ключ = q, где q конкретное значение),
2) по интервалу (а =< ключевое поле р =< в),
3) по близости (|р-q| - минимум, где р-поле, q-значение),
4) по арифметическому условию (например, р1-р2=q и т.п.),
5) по текстовому значению,
6) по совокупности условий.
Поиск по своему содержанию близок процедуре выборки.
Поиск - одна из основных процедур обработки данных, так как удовлетворяет информационные потребности пользователя. Особое значение поиск приобретает в современных условиях при наличии средств телеобработки, телекоммуникаций.
Одним из простых, но эффективных способов поиска является метод дихотомии. Метод дихотомии - это способ поиска данных путем последовательного деления интервала записей упорядоченного массива пополам и выполнения операций сравнения.
Важным критерием в оценке процедуры поиска является время ее выполнения. Как правило, время зависит от числа сравнений по поисковым полям для получения искомой информации. Принимают во внимание как среднее число сравнений Сср, так и Сmax - максимальное число сравнений.
Приведем некоторые оценки поиска для файла из М записей.
| Упорядоченность файла | Метод поиска | Число сравнений Сср среднее | Сmax максимальное |
| Неупорядоченный | Поиск перебором | М | М |
| Упорядоченный | Поиск перебором | (М+1)/2 | М |
| Упорядоченный | Метод дихотомии | 
| 
|
Последовательность поиска в индексно - последовательном файле:
 |
Процедура слияния (объединения) данных. Ключи слияния.
Слияние - процесс обработки двух или более массивов информации, в результате которого получается массив, представляющий собой подмножество данных исходных массивов, записи в котором сформированы по заданным критериям объединения данных.
При слиянии массивов информации часть данных может не найти заданного соответствия и не попадает в результирующий массив. Такие данные называются нестыковкой.
Как правило, слияние (объединение) происходит по совпадению ключевых полей. Для удобства выполнения слияния массивы предварительно сортируют по ключевым полям.
Графическое изображение слияния:
Файл 1 Файл 2
Исходные файлы
 Протокол “Нестыковки”
слияния
Файл 3,
результирующий
Протокол “Нестыковки”
слияния
Файл 3,
результирующий
|
Пример.
Пусть есть два файла, отсортированных по ключу, со структурами записей:
1)
| Табельный номер | Фамилия, и.о. |
2)
| Табельный номер | Сумма |
Нужно получить файл с фамилией, табельным номером и суммой.
3)
| Фамилия, и.о. | Табельный номер | Сумма |
В результате выполнения процедуры слияния двух файлов получим результирующий файл.
Процедура корректировки данных. Виды корректировок. Массив корректур.
Корректировка - это процесс обработки массива информации (файла, набора данных, базы) путем внесения в него изменений с целью обеспечения достоверности и актуальности данных. Корректировка - достаточно сложная процедура.
При корректировке выполняются следующие действия:
- поиск корректируемой записи по ключам и/или места в массиве;
- изменение полей записи;
- удаление записи;
- включение записи.
Виды корректировок:
1) Корректировка последовательного файла.
Недостатки последовательного файла:
- большие затраты на корректировку, связанные с перезаписыванием основного файла (большое время обработки);
- последовательные файлы не используются в он-лайновых системах.
Основной файл и файл корректур отсортированы по ключу (см. схему).
Схема корректировки последовательного файла (массива).
Основной (исходный) файл Файл корректур (изменений)
 
       

Откорректированный файл
|
2) Корректировка в индексно-последовательных и прямых файлах.
Корректировка в индексно-последовательных файлах, файлах прямого доступа, базах данных несколько сложнее.
Для осуществления вставок, включения новых записей или данных используются так называемые “области переполнения”. Области переполнения создаются как в основной области, так и в индексных областях.
При вставке данных они могут попасть в область переполнения, при этом делаются ссылки на добавленную информацию, появляются цепочки данных. При удалении данных, как правило, делаются отметки об удалении в специальном символе (логическое удаление), а физически сама информация не удаляется. При замене данных происходит перезапись физического блока на машинном носителе.
При применении методов прямого доступа, областей переполнения в ряде случаев механизм работы с памятью повторно использует освобожденную память. Для облегчения использования свободных областей они связываются в цепочки. Например, блок памяти будет содержать участки данных вперемешку со свободной памятью:
| данные | свободная память | данные | своб.память | данные | ... | данные | св.память | данные |
При этом участок свободной памяти содержит, как правило, в начале длину участка свободной памяти и ссылку (адрес) на следующий участок свободной памяти:
| L длина участка | А ссылка на следующий участок | свободная память |
| Участок свободной памяти |
Типичная структура индексно-последовательного файла:
 |
индекс основная память
В процессе корректировки участвуют четыре информационных объекта - исходный (основной) массив, в который вносятся изменения, массив корректур (изменений), результирующий (откорректированный исходный) массив и протокол корректировки. Протокол корректировки - это документ, в котором содержится информация о результатах корректировки, обнаруженных ошибках и нестыковках, используемый для анализа и принятия решения по завершению операции корректировки.
В массиве корректур обычно различают 3 типа записей:
1-й тип - “включение”, содержит целиком новую запись, признак “включения”, например, "1";
2-й тип - “удаление”, содержит “ключ” и признак удаления, например, "2";
3-й тип - “замена”, содержит значения заменяемых полей и признак замены, например, "3".
Приведем простой пример корректировки массива информации. Пусть есть массив, состоящий из записей с двумя полями - табельным номером и фамилией, и.о. В него вносится корректура.
Исходный массивРезультатМассив корректур
Таб.N Фио
|
Проблемы корректировки. Реорганизация массива (базы данных, файла).
В результате корректировки происходит изменение физического расположения файла, меняется соответствие между физическим расположением записей и их логической последовательностью (упорядоченностью). Кроме того, могут оказаться заполненными области переполнения файла, что делает невозможным дальнейшее добавление данных даже при наличии свободных участков в основной области файла на машинном носителе.
Для приведения физической и логической организации файла к некоторому исходному состоянию применяются специальные процедуры, которые позволяют перенести данные из области переполнения в основную и подготовить ее для дальнейшего использования, физически удалить логически удаленные записи и т.д. Такие процедуры называют реорганизацией. Для индексно-последовательных файлов реорганизацию подразделяют на процедуру разгрузки (выгрузки) и процедуру загрузки индексно-последовательного файла.
Как часто нужно проводить реорганизацию - это зависит от активности внесения информации (корректировки) и активности использования информации.
В онлайновых системах реорганизация баз данных, файлов проводится в то время, когда абоненты онлайновой системы не работают с ней. Это обычно ночное время или выходные дни. Особая проблема, очень трудная и острая, если базы данных используются круглосуточно. В этом случае необходимо найти такие средства и способы реорганизации баз данных, при которых бы процесс работы с базой данных не прерывался.
При всех видах корректировки необходимо иметь протоколы выполнения корректировки, а в режиме онлайн сохранять сведения о корректировке в отдельном файле (базе) или включать сведения о корректировке в саму базу данных (файл).

Достоверность данных. Перечислить основные группы видов контроля, отдельные методы контроля.
Под достоверностью данных понимается степень неискаженности данных, т.е. степень соответствия данных, внесенных в информационную систему, реальной информации. Достоверность - вероятность того, что в данных есть ошибка.
От достоверности необходимо отличать актуальность данных, которая определяется своевременностью корректировки информации.
Чем меньше ошибок, тем достоверность выше и наоборот, чем больше ошибок, тем достоверность ниже.
Ошибки возникают на различных стадиях:
- на документах при их подготовке;
- при вводе данных оператором;
- сбои оборудования на всех этапах, включая передачу данных по КС;
- ошибки в программном обеспечении;
- и т.д.
Существуют десятки видов контроля, которые обычно подразделяются на группы:
- счетные методы (метод контрольного суммирования, метод итоговых сумм, контроль числа записей и т.д.);
- математические методы (метод корреляционных связей, методы математической статистики и др.);
- методы с избыточной информацией;
- логические методы;
- прочие.
Стадии применения:
- домашинные (операторские);
- программные;
- аппаратурные.
При централизованной обработке данных используют следующие методы контроля:
- визуальный контроль;
- метод двойной набивки (верификации), используется при массовой подготовке информации с доку-ментов в пакетном режиме, дорогостоящ;
- метод контрольного суммирования, часто используется. Этот метод заключается в том, что в доку-менте вводятся дополнительные графы и строки. В эти графы и строки записывается сумма чисел, рас-положенных соответственно в строке или в графе. Эта сумма чисел называется контрольной суммой (КС). Как правило, подсчет контрольных сумм осуществляют операторы (суммировщики) на счетных ма-шинах и вписывают полученные КС в документ. Далее документ подготавливается на машинном носите-ле (“перфорируется”, “набивается”) операторами подготовки данных. Затем, после ввода информации в ЭВМ программным путем вычисляются КС и сравниваются с подсчитанными вручную. Если КС совпали, то документ считается правильно введенным;
- метод итоговых сумм.
Программные методы контроля (как правило, логический контроль):
- контроль по шаблону (цифра, буква и т.п.);
- контроль по структуре данного;
- контроль на границы, т.е. допустимость значений данных;
- контроль взаимосвязанности данных (например, баланс строк и т.п.);
- синтаксический, семантический контроли;
- балансовые методы контроля (проверка сбалансированности строк, столбцов, баланса показате-лей и т.д.);
- другие.
Контроль в аппаратуре:
- контрольное суммирование;
- циклический контроль;
- контроль по чету;
- контроль по модулю;
- другие.
Широкое применение в практике, например, в классификаторах, имеют числовые коды с избыточностью. Для контроля правильности числовых кодов используются дополнительные разряды (чаще один разряд, но может быть два и более), в которых записываются специальным образом вычисленные цифры (контрольные разряды). Вычисляя и проверяя программным путем контрольные разряды можно обнаружить ошибку, а в ряде случаев и исправить ее.
С целью повышения достоверности данных в ИС строится технология обработки данных таким образом, что на всех этапах присутствует контроль данных. Причем, должно быть документально определено кто, что, как и когда выполняет в процессе контроля данных.
Одним из методов повышения уровня защиты от ошибок может быть применение, например, штрих-кодов, магнитных карт и других технических приемов, которые исключают оператора из процесса набора и ввода данных в ЭВМ (систему). Как один из способов ввода информации могут использоваться заранее подготовленные заготовки данных, а оператору остается выбор того или иного варианта, тем самым исключаются ошибки при наборе информации.
Обеспечение безопасности информации. Сохранение и восстановление информации. Схемы копирования и восстановления информации. Контрольная точка.
Сохранение информации - это процедура получения резервной копии с целью ее последующего использования при ликвидации возможных разрушений информации. При сохранении информации используют термины копирование, дублирование, дампирование, выгрузка.
Копирование (сохранение) информации выполняется периодически по графику. Между точками снятия копий сохраняются все данные, которые использовались для внесения изменений в файлы (базы данных). Копирование проводится по схеме “отец-сын”, что означает хранение двух копий для двух последовательных процедур копирования.
Схема копирования.
 Массив накопленных
корректур
Исходный
файл Массив накопленных
корректур
Исходный
файл
 ...
...
Интервал времени t
Копия Копия... Копия
“Отец” “Сын” ...
...
Интервал времени t
Копия Копия... Копия
“Отец” “Сын”
|
При файловой обработке между точками снятия копий сохраняют исходные файлы корректур. При работе с базами данных в режиме онлайн используют системный журнал и процедуру накопления изменений информации. Системный журнал - это файл, в который вносится информация (протоколируется) о ходе работы информационной системы, включая все изменения баз данных.
Восстановление информации - это процедура ликвидации разрушений данных с использованием сохраненной информации на некоторый момент времени (копии) и возможной корректуры с момента создания копии.
В интерактивных (онлайновых) системах предусматривается несколько уровней восстановления:
- оперативное восстановление. Оперативное восстановление используется, когда отдельные изменения в базах данных могут быть отменены при обнаружении ошибок в программах, аргументах поиска данных и т.д.
- промежуточное восстановление. Для целей промежуточного восстановления используется метод контрольной точки. Контрольная точка - это дамп оперативной памяти и/или областей баз данных, сохраняемый в системном журнале в процессе работы информационной системы в определенный момент времени для возможного последующего восстановления работоспособности системы и баз данных на этот момент времени. Контрольная точка создается через заданный интервал времени, через определенное количество изменений в базах данных, при выполнении определенных условий в системе.
- длительное восстановление. Используются копии баз данных для восстановления информации и массивы корректур (накопленных изменений).
При проектировании ИС и создании рабочей документации следует процедуры сохранения и восстановления информации выделять особо. Указанные процедуры входят также в состав функций по ведению баз данных. Ведение базы данных - это комплекс мероприятий по поддержанию данных в актуальном и достоверном состоянии.
Схема восстановления файла.
Файл корректур
Исходный файл (изменения после получения
последней копии)
 Копия
Восстановленный
файл или база данных
Копия
Восстановленный
файл или база данных
|
Защита информации. Безопасность, конфиденциальность, секретность. Закон РФ от 27 июля 2006 года N 149-ФЗ "Об информации, информационных технологиях и о защите информации" о защите информации.
Безопасность - это состояние защищенности информации от внутренних или внешних угроз, от случайного или преднамеренного разрушения, раскрытия или модификации.
Конфиденциальность - это статус, предоставленный данным и согласованный между лицом или организацией, предоставившей данные, и организацией, получающей их. Определяет требуемую степень защиты.
Секретность - это право лица или организации решать, какая информация в какой степени должна быть скрыта от других.
Мероприятия по защите делятся на:
- организационные;
- технические;
- программно-технические;
- криптографические.
Федеральный закон «Об информации, информационных технологиях и о защите информации» — базовый нормативный документ, юридически описывающий понятия и определения области информационной технологии и задающий принципы правового регулирования отношений в сфере информации, информационных технологий и защиты информации, а также регулирует отношения при осуществлении права на поиск, получение, передачу, производство и распространение информации, при применении информационных технологий.
Обеспечение безопасности информации. Организационные мероприятия по защите информации
Организационные мероприятия:
- выявление конфиденциальной информации и ее документальное оформление в виде перечня сведений, подлежащих защите;
- определение порядка установления уровня полномочий субъекта доступа, а также круга лиц, которым это право предоставляется;
- разработка правил разграничения доступа (ПРД);
- ознакомление субъекта доступа с перечнем защищаемых сведений и уровнем полномочий, с организационно-распорядительной и рабочей документацией, требованиями и порядком обработки конфиденциальной информации;
- получение расписки о неразглашении конфиденциальной информации;
- охрана объекта (посты, технические средства охраны зданий, помещений и т.д.) и другие способы, предотвращающие или затрудняющие доступ или хищения СВТ, информационных носителей, НСД к СВТ и линиям связи;
- организация службы безопасности (ответственные лица, администратор АС, специалисты по защите), в т.ч. учет, хранение, выдача информационных носителей, паролей, ключей, ведение служебной информации СЗИ НСД, контроль хода обработки информации и т.д.;
- проектирование, разработка и внедрение СЗИ, приемка СЗИ;
- анализ риска нарушения безопасности информации и планы возможных мероприятий по их ликвидации;
К области организационных мероприятий можно отнести:
- этические нормы поведения сотрудников фирмы, организации, предприятия;
- законодательные акты.
Технические мероприятия по защите информации (применение технических средств защиты).
. Технические мероприятия (применение технических средств для защиты):
- средства защиты от физического доступа (ключи, магнитные карты, кодовые наборы, сейфы и т.п.);
- защита от излучений (экранирование и другие возможные методы);
- средства шифрования автоматические;
- средства измерения параметров КТС, КС, излучений с целью обнаружения отклонения от заданных величин или появления несанкционированных излучений;
- встроенные средства тестирования ВС;
- мини-ЭВМ, микропроцессоры как контролеры безопасности при доступе к информации;
- и другие.
Обеспечение безопасности информации. Программно-технические мероприятия по защите информации (программные средства защиты).
Программно-технические мероприятия (программные средства защиты):
- системы управления доступом; в том числе:
- парольная защита;
- идентификация всех составляющих (терминалов, ЭВМ, КС и т.д.) вычислительной системы;
- контроль доступа в соответствии с матрицей доступа;
- системы регистрации и учета:
- все входы субъекта доступа в систему регистрируются, дата, время, результаты входа сохраняются;
- все выходы регистрируются и результаты выхода;
- выдача документов на печать регистрируются;
- и т.д.
- система обеспечения целостности:
- контроль неизменности программной среды;
- контроль неизменности СЗИ НСД;
- тестирование функций СЗИ НСД при изменениях программной среды и средств ЗИ;
- другие.
Мероприятия по защите информации. Криптографические средства, шифр Цезаря.
Дата добавления: 2015-02-16; просмотров: 220 | Поможем написать вашу работу | Нарушение авторских прав |
|
 ошибка
ошибка ошибка
ошибка