Читайте также:
|
Приведем оценки 45 студентов по курсу статистика в порядке сдачи экзамена:
5 3 3 4 2 4 4 3 5 4 4 5 5 4 4
3 3 3 2 5 5 4 4 4 3 4 3 4 5 4
4 4 4 3 3 4 3 4 3 2 3 2 3 3 3
При таком представлении информации трудно делать какие-либо выводы об успеваемости. Произведем группировку данным путем подсчета количества различных оценок.
оценки 2 3 4 5
количество 4 16 18 7
Как видим, вместо 45 чисел осталось 8, при этом повысилась информативность таблицы, более 50% студентов сдали предмет на хорошо и отлично. Данный пример показывает, что эти данные лучше сгруппировать, то есть разделить их на однородные группы по некоторому признаку. Благодаря группировке данные приобретают систематизированный вид. Если данные систематизированы по времени, то моделью группировки будет временный ряд. Если же по любому другому признаку - то ряд распределения. А для количественных признаков - вариационный ряд.
Пусть Х - одномерный количественный признак и в результате n его измерений наблюдалось n его значений x(1),x(2).....x(n), среди которых могут быть одинаковые. Эти значения называют вариантами. Пусть среди имеющихся n вариант имеется k различных. Причем x1 встречается m1 раз, xk - mk раз. Понятно, что.
Вариационный ряд обычно записывается в одном из видов: в таблице с частотами mi, через относительные частоты Wi=mi/n. В зависимости от типа признака различают дискретные и интервальные вариационные ряды. В зависимости от объема исходных данных и области допустимых значений одномерного количественного признак, частотные распределения также подразделяются на дискретные и интервальные. Если различных вариант очень много (более 10-15), то эти варианты группируют, выбирая определенное число интервалов группировки и получая таким образом интервальное частотное распределение. Алгоритм группировки массива данных состоит из следующих шагов:
Число К обычно берется в пределах 10-15. Редки случаи, когда требуется более 25 и менее 8 группировок. Существуют формулы для определения “оптимального” значения К и построения таким образом оптимального распределения частот. Формула Старджеса. Для больших n эта формула дает оценку снизу для К.
Ранжирование
РАНЖИРОВАНИЕ — расстановка элементов системы по рангу, по признакам значимости, масштабности; установление порядка расположения, места лиц, проблем, целей и задач в зависимости от их важности, весомости.
Обуче́ние ранжи́рованию (англ. learning to rank или machine-learned ranking, MLR)[1] — это класс задач машинного обучения с учителем, заключающихся в автоматическом подборе ранжирующей модели по обучающей выборке, состоящей из множества списков и заданных частичных порядков на элементах внутри каждого списка. Частичный порядок обычно задаётся путём указания оценки для каждого элемента (например, «релевантен» или «не релевантен»; возможно использование и более, чем двух градаций). Цель ранжирующей модели — наилучшим образом (в некотором смысле) приблизить и обобщить способ ранжирования в обучающей выборке на новые данные.
Обучение ранжированию — это ещё довольно молодая, бурно развивающаяся область исследований, возникшая в 2000-е годы с появлением интереса в области информационного поиска к применению методов машинного обучения к задачам ранжирования.
Средняя мода и медиана
Кроме степенных средних в статистике для относительной характеристики величины варьирующего признака и внутреннего строения рядов распределения пользуются структурными средними, которые представлены,в основном, модой и медианой.
Мода — это наиболее часто встречающийся вариант ряда. Мода применяется, например, при определении размера одежды, обуви, пользующейся наибольшим спросом у покупателей. Модой для дискретного ряда является варианта, обладающая наибольшей частотой. При вычислении моды для интервального вариационного ряда необходимо сначала определить модальный интервал (по максимальной частоте), а затем — значение модальной величины признака по формуле:
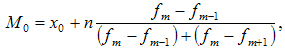
где:
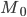 — значение моды
— значение моды — нижняя граница модального интервала
— нижняя граница модального интервала — величина интервала
— величина интервала — частота модального интервала
— частота модального интервала — частота интервала, предшествующего модальному
— частота интервала, предшествующего модальному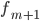 — частота интервала, следующего за модальным
— частота интервала, следующего за модальнымМедиана — это значение признака, которое лежит в основе ранжированного ряда и делит этот ряд на две равные по численности части.
Для определения медианы в дискретном ряду при наличии частот сначала вычисляют полусумму частот  , а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
, а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
Ме = (n(число признаков в совокупности) + 1)/2,
в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
При вычислении медианы для интервального вариационного ряда сначала определяют медианный интервал, в пределах которого находится медиана, а затем — значение медианы по формуле:
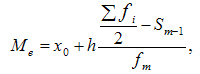
где:
 — искомая медиана — нижняя граница интервала, который содержит медиану — величина интервала
— искомая медиана — нижняя граница интервала, который содержит медиану — величина интервала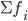 — сумма частот или число членов ряда
— сумма частот или число членов ряда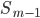 - сумма накопленных частот интервалов, предшествующих медианному — частота медианного интервала
- сумма накопленных частот интервалов, предшествующих медианному — частота медианного интервалаПример. Найти моду и медиану.
| Возрастные группы | Число студентов | Сумма накопленных частот ΣS |
| До 20 лет | ||
| 20 — 25 | ||
| 25 — 30 | ||
| 30 — 35 | ||
| 35 — 40 | ||
| 40 — 45 | ||
| 45 лет и более | ||
| Итого |
Решение:
В данном примере модальный интервал находится в пределах возрастной группы 25-30 лет, так как на этот интервал приходится наибольшая частота (1054).
Рассчитаем величину моды:
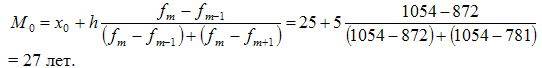
Это значит что модальный возраст студентов равен 27 годам.
Вычислим медиану. Медианный интервал находится в возрастной группе 25-30 лет, так как в пределах этого интервала расположена варианта, которая делит совокупность на две равные части (Σfi/2 = 3462/2 = 1731). Далее подставляем в формулу необходимые числовые данные и получаем значение медианы:

Это значит что одна половина студентов имеет возраст до 27,4 года, а другая свыше 27,4 года.
Кроме моды и медианы могут быть использованы такие показатели, как квартили, делящие ранжированный ряд на 4 равные части, децили -10 частей и перцентили — на 100 частей.
Дисперсия
матем., стат. разброс чего-либо и численная характеристика такого разброса ◆ Этот старый дурак не сообразил, что существует дисперсия свойств… Аркадий Стругацкий, Борис Стругацкий, «Понедельник начинается в субботу», 1964 г. (цитата из Национального корпуса русского языка, см. Список литературы) ◆ В теории вероятностей — дисперсия случайной величины есть математическое ожидание квадрата отклонения случайной величины от её математического ожидания
Среднее квадратическое отклонение
Определение. Средним квадратическим отклонением случайной величины Х называется квадратный корень из дисперсии.
Теорема. Среднее квадратичное отклонение суммы конечного числа взаимно независимых случайных величин равно квадратному корню из суммы квадратов средних квадратических отклонений этих величин.
Пример. Завод выпускает 96% изделий первого сорта и 4% изделий второго сорта. Наугад выбирают 1000 изделий. Пусть Х – число изделий первого сорта в данной выборке. Найти закон распределения, математическое ожидание и дисперсию случайной величины Х.
Выбор каждого из 1000 изделий можно считать независимым испытанием, в котором вероятность появления изделия первого сорта одинакова и равна р = 0,96.
Таким образом, закон распределения может считаться биноминальным.
Пример. Найти дисперсию дискретной случайной величины Х – числа появлений события А в двух независимых испытаниях, если вероятности появления этого события в каждом испытании равны и известно, что М(Х) = 0,9.
Т.к. случайная величина Х распределена по биноминальному закону, то
Пример. Производятся независимые испытания с одинаковой вероятностью появления события А в каждом испытании. Найти вероятность появления события А, если дисперсия числа появлений события в трех независимых испытаниях равна 0,63.
По формуле дисперсии биноминального закона получаем:
Пример. Испытывается устройство, состоящее из четырех независимо работающих приборов. Вероятности отказа каждого из приборов равны соответственно р1=0,3; p2=0,4; p3=0,5; p4=0,6. Найти математическое ожидание и дисперсию числа отказавших приборов.
Принимая за случайную величину число отказавших приборов, видим что эта случайная величина может принимать значения 0, 1, 2, 3 или 4.
Для составления закона распределения этой случайной величины необходимо определить соответствующие вероятности. Примем.
1) Не отказал ни один прибор.
2) Отказал один из приборов.
0,302.
3) Отказали два прибора.
4) Отказали три прибора.
5) Отказали все приборы.
Получаем закон распределения:
| x | |||||
| x2 | |||||
| p | 0,084 | 0,302 | 0,38 | 0,198 | 0,036 |
Дата добавления: 2015-09-10; просмотров: 122 | Поможем написать вашу работу | Нарушение авторских прав |
| <== предыдущая лекция | | | следующая лекция ==> |
| Как накачать грудные мышцы в домашних условиях - упражнения | | | Точечные и интервальные оценки. |