Читайте также:
|
Методика розпізнавання та усунення дублюючих записів в базі даних на основі автоматичного вибору схеми ручної або автоматичної ідентифікації
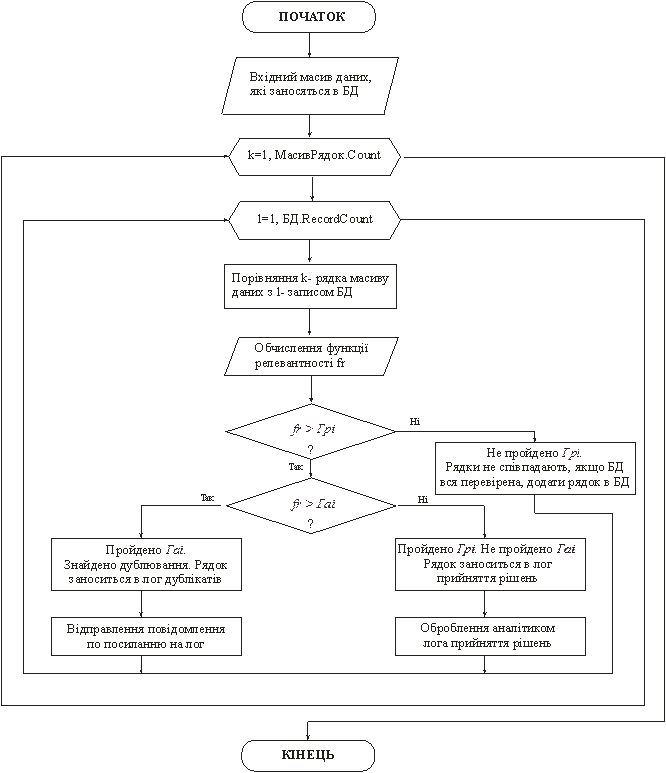
1. На вхід надходить масив даних, який необхідно додати в базу даних, з умовою виключення дублювання даних.
2. Проводиться обчислення значення функції релевантності кожного рядка вхідного масиву з кожним рядком бази даних.
3. Якщо значення функції:
- вище межі автоматичної ідентифікації (Га), після якої кількість розпізнаних дублікатів стає практично рівним 100%, то відповіднтй вхідний рядок оголошуються дублікатом.
- нижче межі ручної ідентифікації (Гр), то рядки для яких обчислюється функція оголошуються різними і аналіз триває.
- вище Гр, але нижче Га, то такі рядки відправляються в лог прийняття рішень для обробки аналітиком.
4. Якщо у якого-небудь рядка вхідного масиву всі значення функції нижче Гр, то даний рядок оголошується новим і додається в базу даних.
У вирішенні задачі виявлення дублікатів в базі даних можна виділити три етапи:
1. Виявлення дублікатів на рівні введення інформації користувачами та їх відхилення;
2. Виявлення дублікатів шляхом порівняння і аналізу уже введених даних відповідно до заданого Га і автоматичне видалення дублюючої інформації;
3. Аналіз та обробка користувачем результатів, які не можуть бути оброблені автоматично (показник відповідності нижче Га але вище Гр).
Алгоритму пошуку та усунення дублювання в базі даних
Третій науковий результат
Дата добавления: 2015-09-10; просмотров: 94 | Поможем написать вашу работу | Нарушение авторских прав |