Читайте также:
|
Статистическая сводка – это научно организованная обработка первичных данных в целях получения обобщающих характеристик изучаемого явления по ряду существенных для него признаков.
Выполнение группировки по количественному признаку:
При составлении структурных группировок на основе количественных признаков определяют количество групп и интервалы группировки.
Интервал – количественное значение, определяющее и отделяющее одну группу от другой, т.е. он очерчивает количественные границы групп.
Интервалы могут быть равные и неравные. Например: по численности работающих предприятия могут быть разбиты на группы: до 100, 100-200, 200-500, 500-1000, 1000 и более. Это объясняется тем, что изменение признака на 50-100 чел. имеет существенное значение для мелких предприятий, а для крупных – не имеет.
Для группировок с равными интервалами величина (длина, шаг) интервала определяется по формуле:
 ,
,
где  ,
,  – наибольшее и наименьшее значение признака;
– наибольшее и наименьшее значение признака;
к – число групп (интервалов), определяемое по формуле Стерджесса:
 ,
,
где N – число единиц совокупности.
Округление полученных в расчетах нецелых чисел производится в большую сторону.
Например: необходимо произвести группировку с равными интервалами 20 рабочих цеха по производительности их труда. Наибольшая производительность 180 деталей за смену, наименьшая – 60.
Количество групп: 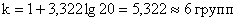
Длина интервала: 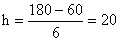 дет.
дет.
Нижняя граница 1-ой группы 60 деталей, верхняя 60+20=80 деталей. Вторая группа: нижняя граница 80, верхняя 80+20=100 и т.д. В результате получаем такой интервальный ряд (или такие группы рабочих), деталей:
1 группа: 60-80
2 группа: 80-100
3 группа: 100-120
4 группа: 120-140
5 группа: 140-160
6 группа: 160-180
В этом распределении имеется неопределенность, к какой группе отнести единицу совокупности, значение признака которой равно граничному значению интервала (рабочих с производительностью 80, 100, 200 и т. д. дет/см). Для устранения неопределенности используют принцип единообразия: левая, нижняя граница интервала включает в себя указанное значение, а верхняя – нет. Значит, рабочего, производящего 100 дет/см, относят к 3 группе.
Интервалы групп могут быть закрытыми, когда указаны верхняя и нижняя границы (как в примере), и открытыми, когда указана лишь одна из границ. Например, интервалы «менее 60» или «180 и выше» - открытые интервалы.
Дата добавления: 2015-01-30; просмотров: 117 | Поможем написать вашу работу | Нарушение авторских прав |
|